DIY 배달 서비스 플랫폼 API 서버 - 3장. 시스템 설계
21 Apr 2021개요
비즈니스 예시(배달 서비스)를 토대로 도메인 설계부터 배포까지 직접 구현해 보고 작동 원리를 자세하게 공부하는 프로젝트입니다. 처음 어떤 아이템을 만들지 고민하는 과정부터 문제 해결(아이템 개발)을 하기 위한 전략과 도구 선택, 프로젝트 관리, 구현 및 배포까지 프로젝트가 진행되는 모든 발자취를 기록합니다. 더 좋은 구현 방법, 더 효율적인 설계, 잘못된 내용이 있다면 이곳을 통해 언제든 리뷰해 주시면 감사하겠습니다.
Table of Contents
3장. 시스템 설계
해당 프로젝트는 가상 비즈니스 상황을 가정하고 가상 서비스에 대한 API 서버를 구현합니다.
이전 장에서는 도메인 설계를 통해 마이크로 서비스가 될 후보들을 선정하였습니다.
이번 장은 마이크로 서비스들을 중심으로 커다란 골격, 즉 시스템 구성을 설계해보도록 하겠습니다.
3-1. 외부 아키텍처 정의
우선 마이크로 서비스 아키텍처의 예시입니다.
(각 구성요소들은 변경/대체 가능합니다)
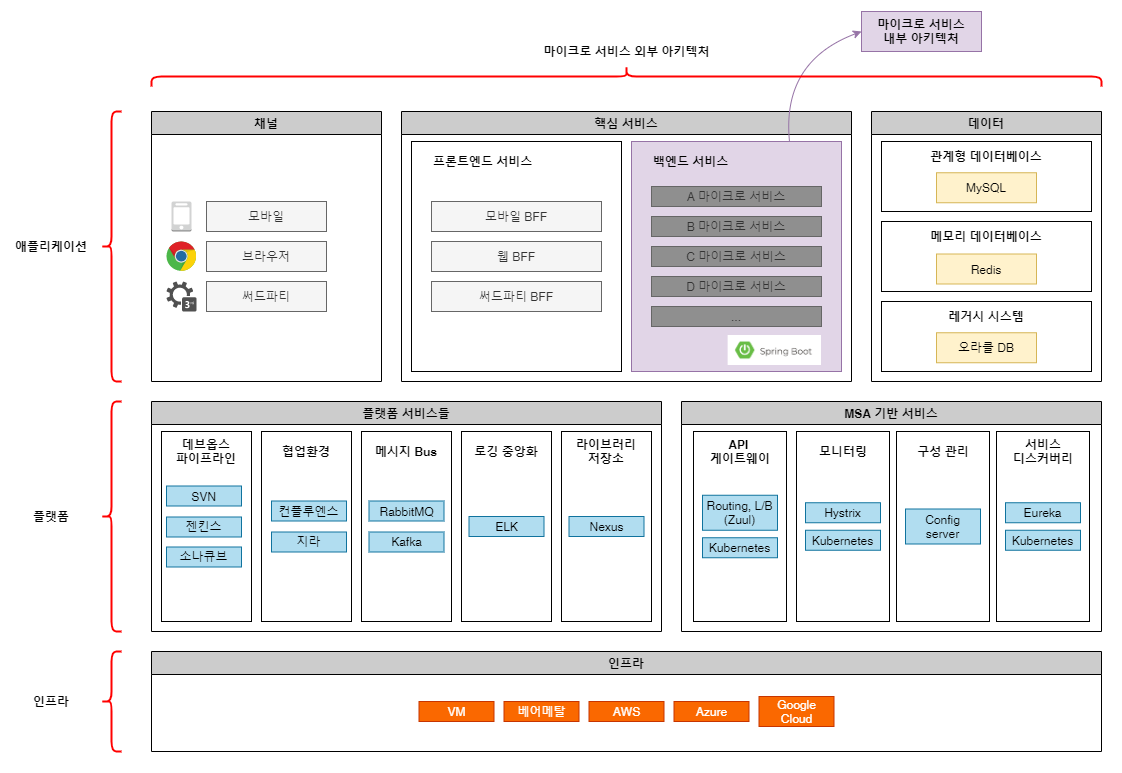
- 인프라
서비스 운용의 기반이 되는 하드웨어 인프라입니다.
온프렘(On-premise) 환경이나 클라우드 서버에 플랫폼를 올려 구동/운영합니다.
- 플랫폼
인프라 영역 위에 어플리케이션을 구동/운영하기 위한 플랫폼이 올라갑니다.
코어 서비스 어플리케이션이 잘 작동하도록 도와주는 플랫폼 서비스들(메시지 브로커, 데브옵스 파이프라인 등)이 해당됩니다.
- 어플리케이션
마이크로 서비스의 핵심을 담당하는 각 비즈니스 서비스와 데이터가 올라갑니다.
서로다른 언어로 개발된 여러 어플리케이션이 구동될 수 있습니다 (폴리그랏).
위 각 영역에 있는 구성요소 및 그것들의 관계, 서비스 운영 환경을 정의하는 것을 MSA 외부 아키텍처라 합니다.
(마이크로 서비스를 관리하고 운영하기 위한 어플리케이션도 모두 포함됩니다)
3-2. MSA 패턴
앞에서 설명한 아키텍처는 문제 영역에 대한 솔루션을 제공하는 것입니다.
그렇다면 어떤 문제영역이 있고 어떤 해법으로 그 문제를 해결할까요?
이처럼 어떤 문제 영역에 대해 여러 사람들에 의해 검증되어 정리된 유용한 해법을 패턴(Pattern)이라고 합니다.
MSA 에도 이러한 설계 패턴들이 존재합니다.
마이크로 서비스 패턴 종류는 다음과 같습니다.
패턴을 편하게 구현하도록 도와주는 여러 오픈소스들을 아래에 같이 적어놨습니다.
넷플릭스 OSS 는 MSA 관련 패턴들을 정형화하여 오픈소스화 한 프로젝트입니다.
하지만 넷플릭스 OSS 또한 각 패턴별 러닝커브가 존재하고 알아야 할 종류들이 많습니다.
보통 대규모 시스템을 운영하는 기업들은 쿠버네티스를 사용하여 여러 패턴에 쓰이는 기술들을 안정적이고 효율적으로 운영합니다.
쿠버네티스에 관한 설명은 아래 링크를 참조해주세요.
[ 쿠버네티스 알아보기 ]
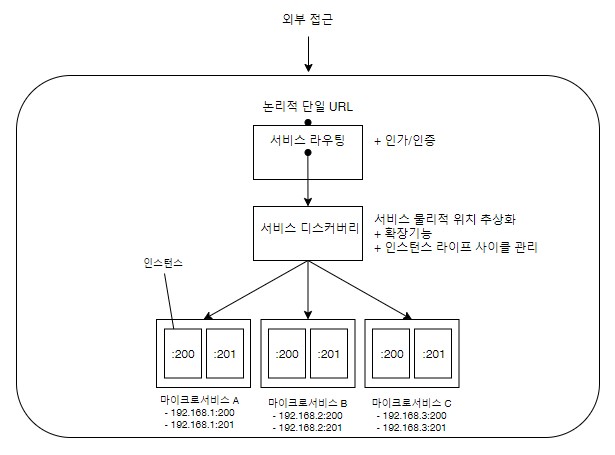
- 라우팅 패턴
- 서비스 디스커버리 패턴
- 스프링 클라우드 + 넷플릭스 유레카
- 쿠버네티스
- 서비스 라우팅 패턴
- 스프링 클라우드 + 넷플릭스 주울
- 쿠버네티스
- 서비스 디스커버리 패턴
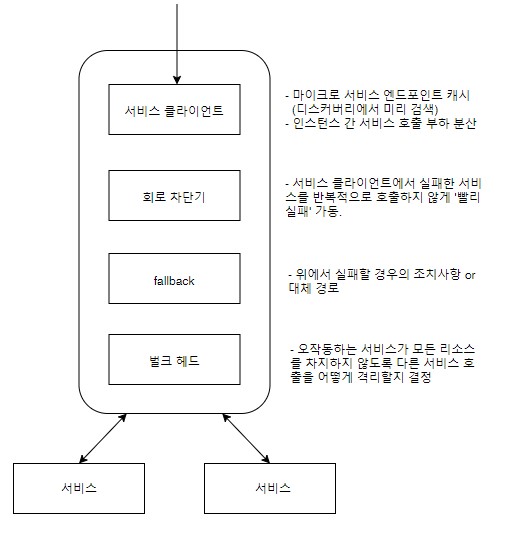
- 회복성 패턴
- 클라이언트 부하 분산
- 스프링 클라우드 + 넷플릭스 리본
- 쿠버네티스
- 회로차단기 패턴
- 스프링 클라우드 + 넷플릭스 히스트릭스
- 폴백 패턴
- 스프링 클라우드 + 넷플릭스 히스트릭스
- 벌크 헤드 패턴
- 스프링 클라우드 + 넷플릭스 히스트릭스
- 클라이언트 부하 분산
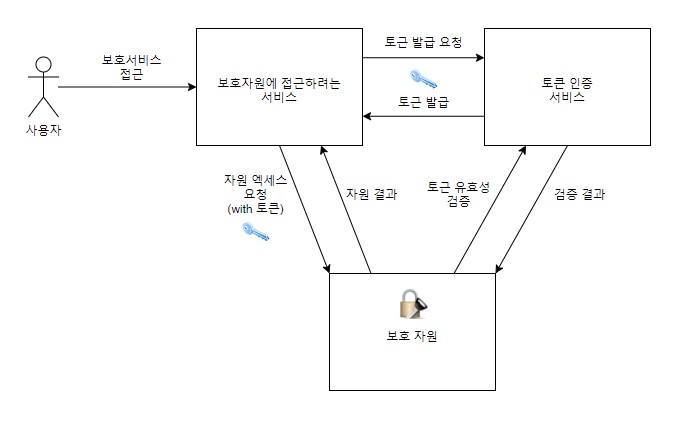
- 보안 패턴
- 스프링 클라우드 시큐리티
- OAuth2, JWT
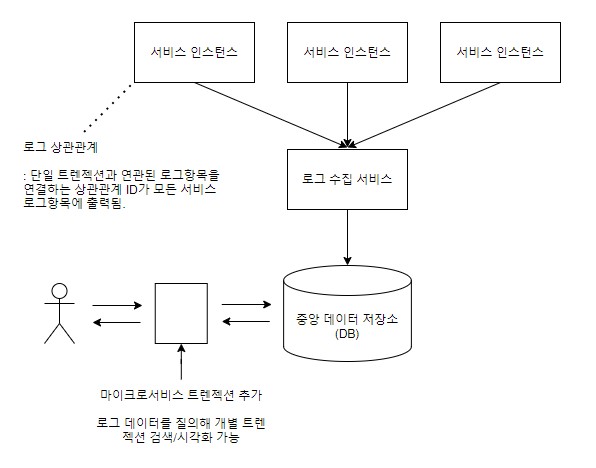
- 로그 패턴
- 스프링 클라우드
- 슬루스
- 페이퍼 트레일
- 집킨
- 빌드/배포 패턴
- 지속적 통합(CI)
- Travis CI
- 쿠버네티스
- 코드형 인프라스트럭처 (IaC)
- 도커
- 불변서버
- 도커
- 피닉스서버
- Travis CI
- 도커
- 지속적 통합(CI)
- 개발 패턴
- 핵심 마이크로서비스 패턴
- 스프링 부트
- 구성 관리
- 스프링 클라우드 컨피그
- 비동기 메시징
- 스프링 클라우드 스트림
- 핵심 마이크로서비스 패턴
3-3. 마이크로 서비스 패턴
MSA 를 통해 서비스를 제공하려면 우선은 인프라가 구축돼야 하고,
그 위에 미들웨어가 올라가고, 미들웨어 위에서 어플리케이션이 동작해야 합니다.
| 패턴 유형 | 설명 |
|---|---|
| 인프라 구성요소 | 마이크로 서비스를 지탱하는 하부구조 인프라를 구축하는 데 필요한 구성요소 |
| 플랫폼 패턴 | 인프라 위에서 마이크로 서비스의 운영과 관리를 지원하는 플랫폼 차원의 패턴 |
| 어플리케이션 패턴 | 마이크로 서비스 어플리케이션을 구성하는 데 필요한 패턴 |
마이크로 서비스가 동작하고 운영되는 그릇인 외부 아키텍처를 중심으로, 시스템의 기반을 지탱하는 인프라 구성 요소부터 살펴보겠습니다.
3-3-1. 인프라 구성요소
인프라란 엔터프라이즈 IT 환경을 운영/관리하는 데 필요한 근간이 되는
- 하드웨어
- 소프트웨어
- 네트워크 구성요소
- 운영체제
- 데이터 스토리지 등
을 모두 포괄하는 영역입니다.
클라우드 환경에서는 이러한 인프라 구성요소가 가상화되어 제공됩니다.
3-3-2. 클라우드 환경
예전에 오랜 시간에 걸쳐 힘들게 구축했던 인프라를 이제는 AWS, 구글, 마이크로소프트, IBM 등 세계적인 플랫폼 사업자들이 자동화된 Iaas (Infrastructure as a Service), Paas (Platform as a Service) 서비스를 통해 쉽고 편하게 이용할 수 있게 해줍니다.
시스템의 자원 구성, 할당, 관리, 모니터링 등의 설정작업을 몇 번의 클릭만으로 가능하게 합니다.
하지만 클라우드 환경에서도 아키텍트가 고려해야 할 일들은 여러가지가 있습니다.
- 하부 시스템의 기반이 되는 인프라 구축
- 베어 메탈 장비에 인프라를 구축할지, 가상화 환경을 선택할지 결정
- 가상화 환경에서 퍼블릭 Iaas, PaaS 를 선택할지, 직접 구매할지, 베어 메탈 서버에 프라이빗 PaaS 를 구축할지 결정
마이크로 서비스는 어떠한 장비에도 구동될 수 있습니다.
그렇지만 가상화 장치 없이 구동한다면 인프라의 유연한 확장/축소를 기대하기 힘든 무모한 작업이 됩니다.
(MSA 시스템을 위한 베어 메탈을 고려한다면 그것은 베어 메탈에 별도의 프라이빗 클라우드 환경을 구축하는 것을 의미합니다)
따라서 MSA 는 가상 인프라 환경을 환경을 이용하는 것이 효율적입니다.
인프라를 선택하였다면, 다음으로 가상머신과 컨테이너 기반 제품을 고민해보겠습니다.
3-3-3. VM과 컨테이너
두 기술 모두 가상의 공간을 만들어내는 공통점이 있습니다.
하지만 자세하게 살펴보면 완전히 다른 점들이 있습니다.
- 가상머신(VM; Virtual Machine)
하이퍼바이저(Hypervisor)라는 소프트웨어를 이용해 하나의 시스템에서 여러 개의 OS(운영체제)를 사용하는 기술- 일반적으로 크기가 기가바이트 단위
- 게스트 OS 를 사용하기에 OS 패치 설치, 라이브러리 설치 등 오버헤드가 지속적으로 발생
- 컨테이너
하이퍼바이저 없이 컨테이너 엔진을 사용해 가상의 격리된 공간을 생성- 일반적으로 크기가 메가바이트 단위
- 작은 서비스를 패키징하고 배포하기에 적합 (실행에 필요한 모든 파일이 컨테이너에 패키징 되지 않음)
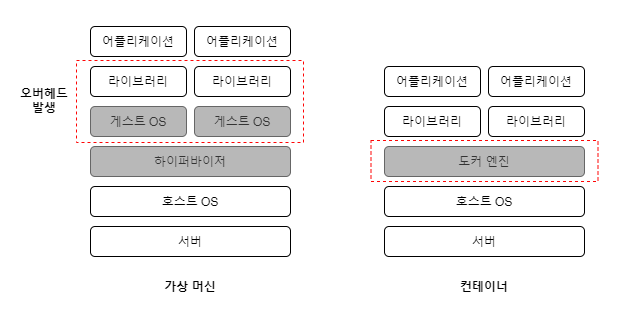
MSA 에서는 작은 서비스 단위로 잦은 배포가 이루어지므로 컨테이너 환경이 유리합니다.
마이크로 서비스의 가변적이고 유연한 속성을 컨테이너가 쉽고 빠르게 지원할 수 있기 때문입니다.
가장 대표적인 컨테이너 기술로는 도커가 있습니다.
도커에 관한 설명은 이곳을 참조해주세요.
3-3-4. 컨테이너 오케스트레이션
도커 외에도 Unikernels, LXD, OpenVZ, RKt 등 컨테이너 기술들이 있습니다.
컨테이너 기술을 선택하셨다면 컨테이너를 관리하기 위한 기술 또한 필요합니다.
왜 필요한가?
컨테이너가 많아지면 그에 따른 관리가 필연적입니다.
- 컨테이너의 자동 배치 및 복제
- 컨테이너 장애 복구
- 컨테이너 확장 및 축소
- 컨테이너 간 통신 관리
- 로드 밸런싱 등
이 밖에도 여러 필요에 따른 관리 기술들이 필요해집니다.
이러한 컨테이너 관리 기술을 통틀어 컨테이너 오케스트레이션 이라 합니다.
오케스트레이션 도구로는 Docker Swarm, Apache Mesos,
그리고 최근 구글이 자사의 도커 컨테이너 관리 노하우를 바탕으로 만든 Kubernetes 가 있습니다.
쿠버네티스에 관한 설명은 이곳을 참조해주세요.
3-3-6. 클라우드 인프라 서비스
클라우드 인프라 선택지는 매우 다양합니다.
위 클라우드 환경에서 설명하였듯이 여러 사업자들이 많은 인프라 시스템을 제공합니다.
- AWS
- Azure
- Google Cloud 등
MSA 시스템으로 간다고 하면 쿠버네티스는 아니지만 동일하게 컨테이너 기반인
- AWS Elastic Beanstalk
- Elastic Container Service(ECS)
- Azure Web App
- Google App Engine 등 여러 PaaS 를 고려할 수 있습니다.
PaaS(Platform as a Service) : 복잡함 없이 어플리케이션을 곧바로 개발, 실행, 관리할 수 있는 플랫폼 환경을 서비스 형태로 제공합니다. IaaS 위에 미들웨어나 런타임까지 탑재된 환경이라 생각하면 됩니다.
여기까지 마이크로 서비스를 적재하기 위한 기반이 되는 클라우드 인프라 요소를 살펴보았습니다.
다음으로는 마이크로 서비스의 원활한 동작을 지원하는 플랫폼 환경을 살펴보겠습니다.
3-4. 플랫폼 패턴
인프라 환경 위에서 어플리케이션을 운영/관리/빌드/배포하는 환경을 구성하는 방법을 생각해봐야 합니다.
마틴 파울러가 강조했듯이 MSA 시스템을 구성하는 수많은 마이크로 서비스를 하나하나 수동으로 빌드/배포한다면 엄청나게 비효율적입니다. 이러한 과정을 하나하나 통제하고 자동화하는 것이 중요합니다.
3-4-1. 데브옵스 인프라 구성
마이크로 서비스를 (자동으로) 빌드하고 테스트한 뒤 배포할 수 있게 도와주는 개발 지원 환경을 데브옵스(DevOps)환경이라 합니다.
(보통 개발+운영 을 병행하는 조직 또는 문화를 뜻하는데, 여기서는 자동화 환경의 의미로 사용하겠습니다)
과거 수동 빌드/배포 과정은 매우 많은 시간이 소요되었습니다.
또한 배포 때마다 시스템을 중단한 뒤 배포 작업을 진행하는 경우가 많았습니다.
하지만 MSA 환경에서는 잦은 배포가 이루어져야 하므로 배포의 자동화와 무중단 배포가 절실합니다.
자동화된 빌드/배포 작업을 CI/CD 라 합니다.
-
CI (Continuous Integration; 지속적 통합)
오랜 시간이 걸리는 빌드를 자동화하여 개발 생산성과 소스코드 품질을 높입니다.
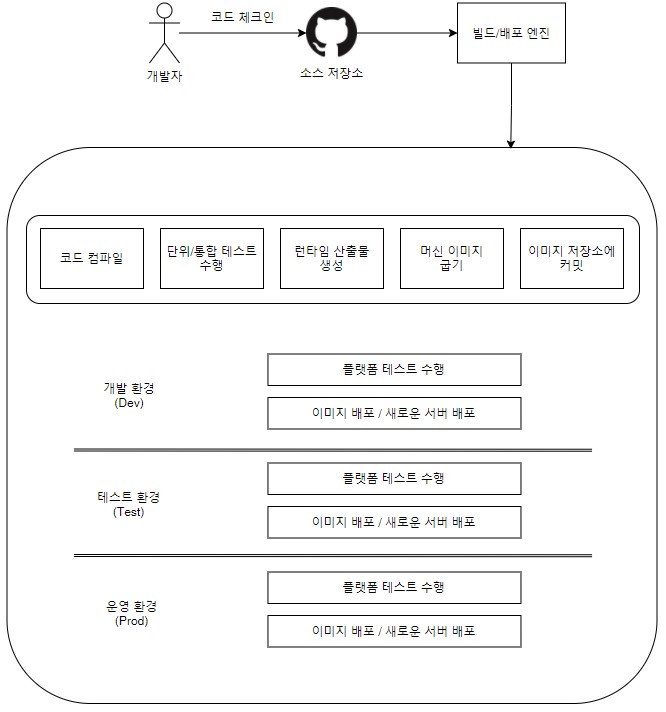
자동으로 통합 및 테스트하고 그 결과를 리포트로 기록합니다.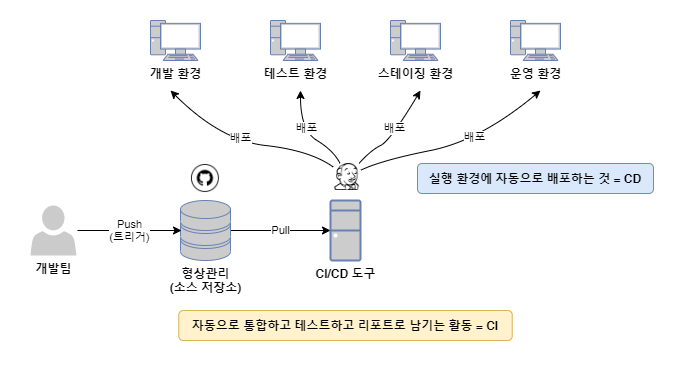 그림 2 - 자동 빌드 및 배포 절차
그림 2 - 자동 빌드 및 배포 절차
-
CD (Continuous Deployment; 지속적 배포)
소스코드 저장소에서 빌드한 소스코드의 실행 파일을 실행 환경까지 자동으로 배포하는 방식을 뜻합니다.
다른 의미의 CD (지속적 제공; Continuous Delivery) 와의 차이는 엄격한 배포 절차에 있습니다.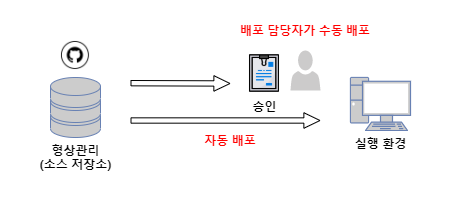 그림 3 - Continuous Deployment 와 Continuous Delivery 차이
그림 3 - Continuous Deployment 와 Continuous Delivery 차이
3-4-2. 빌드/배포 파이프라인 설계
빌드/배포 과정 동안 수행해야 할 테스크가 정의된 것을 빌드/배포 파이프라인이라고 합니다.
전형적인 파이프라인 흐름도는 다음과 같습니다.

배포 절차 전에 UI 테스트, 통합테스트, 배포 승인 프로세스 등을 추가하여 재설계할 수도 있습니다.
위와 같은 일련의 프로세스를 하나로 연계해서 자동화하고 시각화한 절차로 구축합니다.
3-4-3. Infrastructure as Code
인프라 구성을 마치 프로그래밍하는 것처럼 처리하여 소수의 인원으로 많은 컨테이너 배포 처리를 하는 것을 뜻합니다.
- 배포 파이프라인 절차를 완벽하게 자동화
- 대규모 인프라 관리
- 쉬운 공유/재사용
Infrastructure as Code 를 통해 자동화할 요소들로는 다음과 같습니다.
- 형상관리 리포지토리에서 소스코드를 가져와 빌드하여 실행 파일을 만드는 작업
- 실행 파일을 실행 환경에 배포하는 작업
- 연계 자동화 작업 (위 작업들을 통제/연결하여 전 작업이 성공하면 다음 작업이 자동으로 수행)
위 요소들을 모두 코드로 정의/설정할 수 있고 이를 지원하는 여러 오픈소스나 솔루션이 있습니다.
MSA 서비스 마다 각자 다른 빌드/배포 파이프라인을 설계하고 자동/수동화를 적용할 수 있습니다.
3-4-4. 마이크로 서비스 생태계
마이크로 서비스가 어떻게 발전했는지 흐름을 살펴보겠습니다.
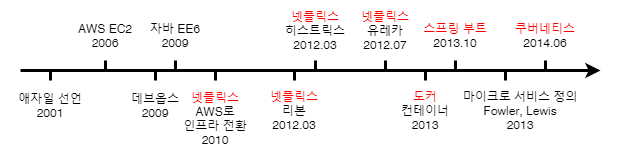
이전 설명했던 CI (지속적 통합) 개념이 켄트 벡에 의해 XP 방법론의 프랙티스로 소개됩니다.
그 후 켄트 벡, 켄 슈와버, 마틴 파울러 등 여러 구루들이 모여 2001년 ‘애자일 선언’ 을 하게 됩니다.
장기적인 계획이나 단계적 프로세스로 개발을 해온 소프트웨어 업계에 변화의 바람이 불기 시작합니다.
빠른 실패와 빠른 피드백을 기반으로 하는 애자일의 실용적인 실천법으로 개발 흐름이 점점 변화하게 됩니다.
2006년 아마존의 IaaS 서비스인 EC2 를 시장에 최초로 발표하며 대 클라우드 시대가 열리게 됩니다.
그즈음 (DVD 대여 서비스로 출발했던) 넷플릭스가 스트리밍 사업을 시작하게 되는데, 스트리밍 데이터베이스의 스토리지가 손실되는 대규모 서비스 장애를 겪게 됩니다.
이를 계기로 넷플릭스는 기존 (한 덩어리의) 모노리스 시스템에서 마이크로 서비스 시스템으로 전환하는 작업을 시작하게 됩니다.
(이때 선택한 클라우드가 AWS EC2 입니다)
넷플릭스는 마이크로 서비스 전환 과정을 거치면서 여러 풍파를 겪게 됩니다.
- 기존 모노리스 시스템에서는 고려하지 않아도 될 문제점들이 점점 발생
- 발생 장애가 다른 서비스에게 전파
- 여러 서비스에 분산된 로그 관리 문제
- 장애 모니터링 등
넷플릭스는 경험에 기반한 문제해결 도구를 개발하게 됩니다.
그리고 넷플릭스 기술력에 의구심을 갖는 사람들에게 보란듯이 오픈소스로 공개합니다.
그것이 바로 넷플릭스 OSS 입니다.
넷플릭스 OSS 는 여러 마이크로 서비스 운영 환경을 위한 서비스를 제공합니다.
- 마이크로 서비스 간의 라우팅과 로드 밸렁신을 위한 줄(Zuul) 과 리본(Ribbon)
- 모니터링을 위한 히스트릭스(Hystrix)
- 서비스 등록/디스커버리를 위한 유레카(Eureka) 등
이러한 오픈소스를 통해 기술들이 공유되며 마이크로 서비스 업계가 빠르게 발전되게 됩니다.
이후 2013년 컨테이너 기술인 도커가 등장하게 됩니다.
또한 이쯤에 스프링 진영에서 마이크로 서비스를 쉽게 개발할 수 있는 프레임워크인 스프링 부트를 발표합니다.
최근 구글에서는 컨테이너 오케스트레이션 기술인 쿠버네티스 까지 등장하게 됩니다.
이러한 수많은 과정들을 거쳐 마이크로 서비스는 계속 끊임없이 발전되고 있습니다.
위 발전 흐름을 통해 생겨난 문제 해결 패턴들이 존재합니다. 그 패턴들을 하나하나 알아보겠습니다.
3-4-5. 마이크로 서비스 관리/운영 패턴
마이크로 서비스 구축 시 발생하는 문제는 주로 여러 개의 시스템 구성 방식 때문에 발생하게 됩니다.
앞에서 언급했다시피 넷플릭스는 이러한 문제를 해결하는 데 크게 기여했습니다.
넷플릭스 OSS 는
- API 게이트웨이
- 서비스 디스커버리
- 모니터링
- 트레이싱 등
다수의 마이크로 서비스를 관리/운영하기 위한 플랫폼 패턴을 제공합니다.
또한 스프링 진영에서는 기존 스프링 부트 프레임워크에 넷플릭스 OSS 가 잘 작동하도록,
넷플릭스 OSS 모듈들을 감싸 스프링 클라우드(Spring Cloud) 라는 명칭으로 내놓았습니다.
스프링 부트와 스프링 클라우드를 이용하면 마이크로 서비스 어플리케이션 운영 환경을 쉽게 구축할 수 있게 됩니다.
이어서 스프링 클라우드를 중심으로 주요 관리/운영 플랫폼 패턴을 살펴보겠습니다.
3-4-6. 스프링 클라우드
스프링 클라우드는 넷플릭스 OSS(Zuul, Eureka, Hystrix, Ribbon 등)를 스프링 프레임워크 기반으로 사용하기 쉽게 통합한 것입니다.
스프링 클라우드 기반으로 동작하는 서비스 연계 흐름은 다음과 같습니다.
- 환경 설정 정보를 형상관리 시스템에 연계된 Config 서비스에서 가져와 설정 정보를 주입 후 클라우드 인프라의 개별 인스턴스로 로딩.
- 모든 마이크로 서비스를 인프라에 종속되지 않도록 설정파일을 분리
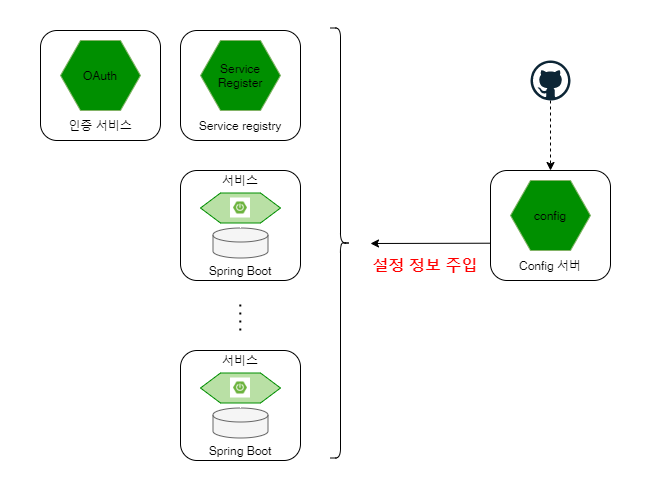 설정 정보 주입
설정 정보 주입
-
로딩과 동시에 ‘서비스 레지스트리’에 자신의 서비스명과 클라우드 인프라로 부터 할당받은 물리 주소를 매핑해서 등록.
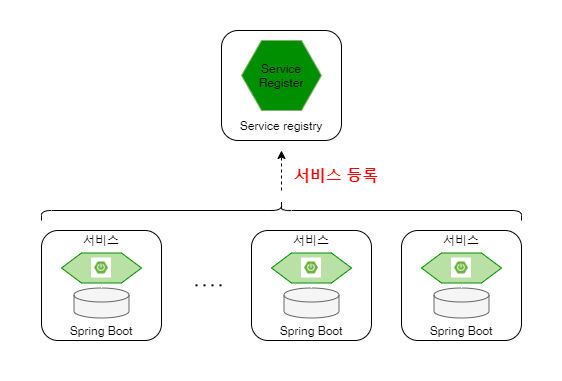 서비스 등록
서비스 등록
-
클라이언트가 ‘API 게이트웨이’를 통해 마이크로 서비스에 접근하고, 이때 API 게이트웨이는 적절한 라우팅 및 부하 관리를 위한 로드 밸런싱 추가.
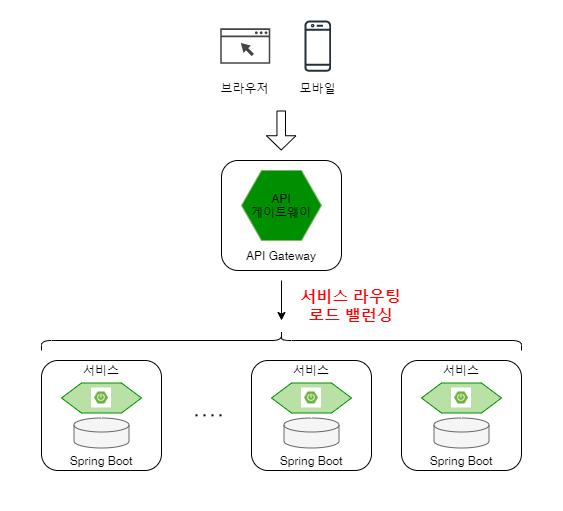 API 게이트웨이
API 게이트웨이
-
API 게이트웨이에서 클라이언트가 마이크로 서비스에 접근하기 위한 주소를 알기 위해 ‘서비스 레지스트리’ 검색을 통해 서비스의 위치 반환.
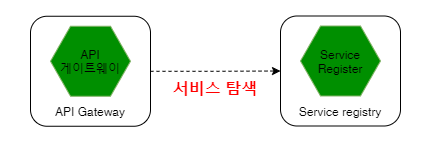 서비스 디스커버리
서비스 디스커버리
-
동시에 API 게이트웨이는 클라이언트가 각 서비스에 접근할 수 있는 권한이 있는지 ‘인증 서비스’와 연계하여 인증/인가 처리를 수행.
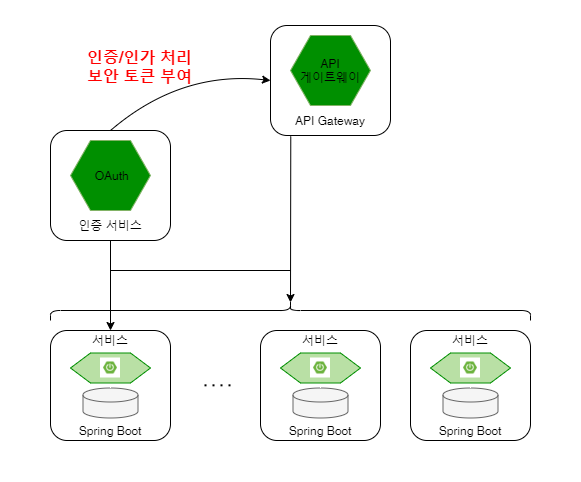 서비스 인증/인가
서비스 인증/인가
-
이러한 모든 마이크로 서비스 간의 호출 흐름은 ‘모니터링 서비스’와 ‘추적 서비스’에 의해 모니터링/추적 됩니다.
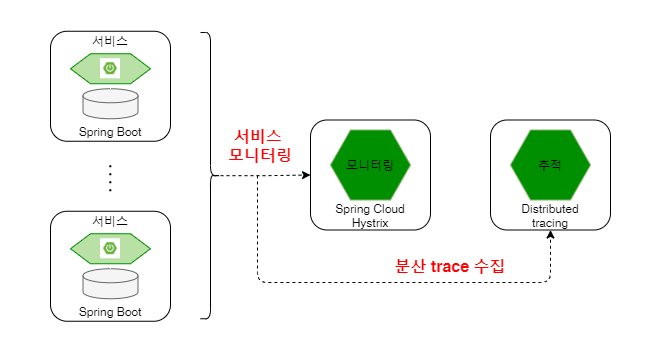 모니터링/추적
모니터링/추적
전체 아키텍처는 다음과 같습니다.
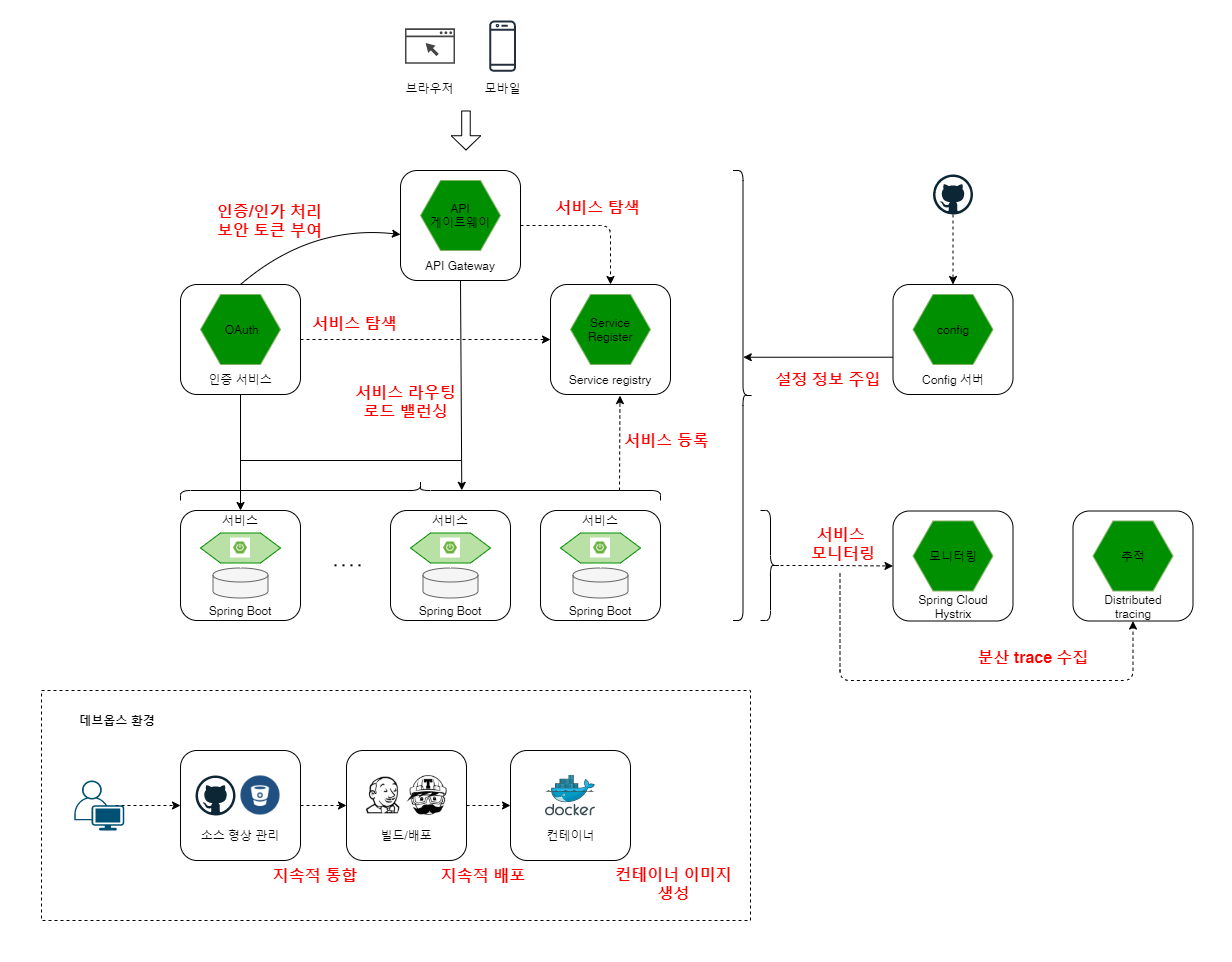
3-4-7. 점점 비대해지는 운영/관리…
위에서 살펴본 Spring Cloud + Netflix OSS 패턴은 모두 모노리스 시스템이 여러 조각조각으로 나뉘어져서 발생하는 문제들을 해결합니다.
하지만 각 문제들마다 상이한 기술들로 해결하므로 해결 자체의 복잡성 또한 증가되고 있습니다.
이후 여러 문제의 해결책을 한꺼번에 제공하는 솔루션들이 등장하게 됩니다.
바로 쿠버네티스나 오픈시프트와 같은 제품들입니다.
특히 인프라 유연성을 보장하기 위해 AWS IaaS 의 인프라 차원에서 해결 했던 역할을 쿠버네티스가 소프트웨어 차원, 즉 컨테이너의 레플리카 기술로 탐색, 호출 문제와 함께 통합해서 지원하면서 쿠버네티스가 각광받고 있습니다.
최근 동향은 쿠버네티스와 덧붙여 이스티오(Istio) 기술이 함께 사용되고 있습니다.
3-4-8. 서비스 메시 패턴
위에서 언급하였듯이 Spring Cloud + Netflix OSS 기반의 서비스를 구축/운용할 때의 문제점은
운영 관리를 위한 여러 개의 기반 서비스를 별도로 각각 만들어야 한다는 번거로움이 있다는 것입니다.
또한 업무 처리 마이크로 서비스에 ‘스프링 클라우드 서비스를 사용하기 위한 라이브러리’ 를 비지니스 로직과 ‘함께 탑재’ 해야 한다는 점입니다.
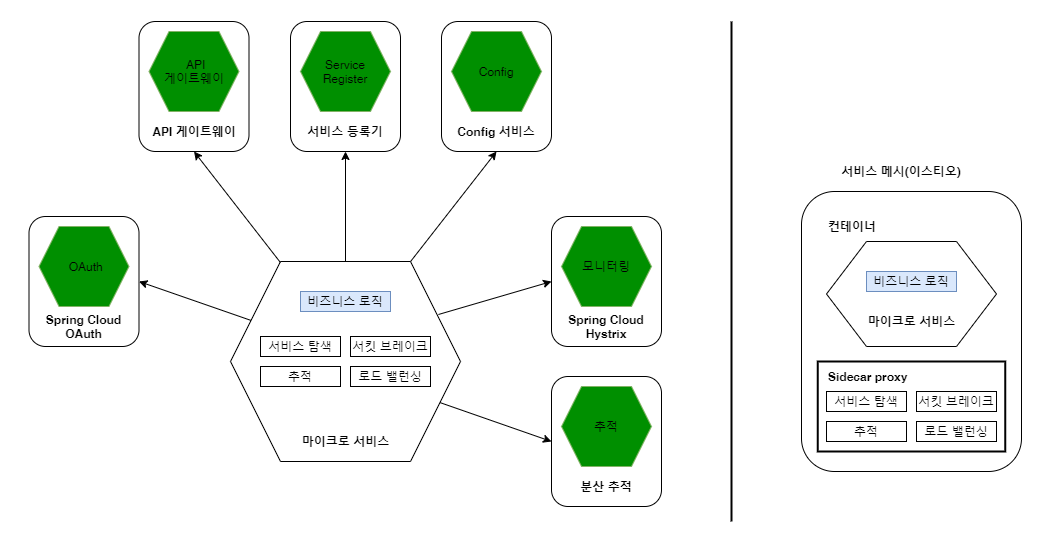
또한 스프링 클라우드는 자바 기반이기 떄문에 마이크로 서비스가 자바 외의 다른 언어로 구현(폴리그랏)된 경우에는
스프링 클라우드 서비스를 아예 사용할 수조차 없게됩니다.
서비스 메시 패턴이란,
MSA 문제 영역 해결을 위한 기능
- 서비스 탐색
- 서킷 브레이크
- 추적
- 로드 밸런싱 등
을 비즈니스 로직과 분리해서 네트워크 인프라 계층에서 수행하게 합니다.
서비스 메시는 인프라 레이어로서 서비스 간의 통신을 처리하며 앞에서 언급한 여러 문제 해결 패턴을 포괄합니다.
서비스 메시 패턴의 대표적 구현체로 이스티오(Istio)가 있습니다.
이스티오는 어플리케이션이 배포되는 컨테이너에 완전히 격리되어 별도의 컨테이너로 배포되는 사이드카(Sidecar) 패턴을 적용합니다.
(서비스 디스커버리, 라우팅, 로드 밸런싱, 로깅, 모니터링, 보안, 트레이싱 등의 기능을 대체합니다!)
사이드카 패턴이란, 모든 서비스 컨테이너에 사이드카 컨테이너가 추가로 배포되는 패턴입니다.
각 서비스를 연계할 때 한 서비스가 다른 서비스를 직접 호출하지 않고 사이드카인 Proxy 를 연계하여 개발자가 별도의 작업 없이 관리/운영에 대한 서비스 등을 적용할 수 있습니다.
기본적으로 이스티오는 쿠버네티스에 탑재되어 이러한 서비스 메시 기능을 지원합니다.
이러한 기능으로 마이크로 서비스는 순수 비즈니스 로직에 집중할 수 있게 됩니다.
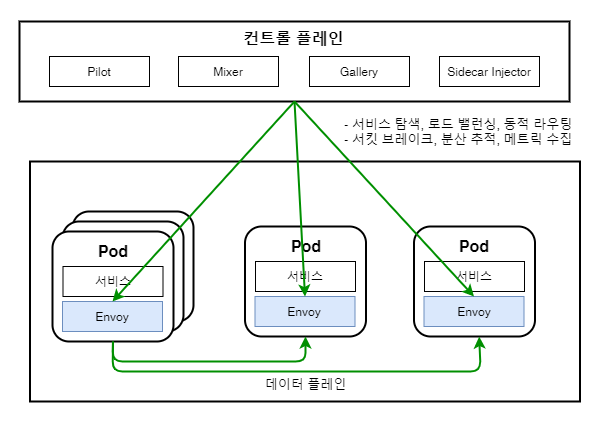
- 컨트롤 플레인 기능에 의해 중앙에서 통제되며, 사이드카끼리 통신해서 관련 운영 관리 기능을 제공합니다.
(이를 통해 마이크로 서비스 비즈니스 로직과는 완벽하게 독립됩니다) - 쿠버네티스의 컨테이너 단위인 파드(pod)에 서비스 컨테이너와 사이드카 구현체인 엔보이(Envoy) 컨테이너가 함께 배포된 것을 볼 수 있습니다.
이스티오가 가지는 차별점은 다음과 같습니다.
- 애플리케이션 코드 변경이 거의 없음. (사이드카 격리, 설정파일(yaml)에 의해 정의됨)
- 폴리그랏 어플리케이션 지원 가능. (스프링 클라우드 + 넷플릭스 OSS 의 경우 자바 언어만 지원)
- 쿠버네티스와 완벽하게 통합된 환경 지원.
3-5. 내부 아키텍처 정의
실제로 비즈니스가 실행되는 비즈니스 어플리케이션의 구조를 정의하는 것을 MSA 내부 아키텍처라 합니다.
내부 아키텍처를 정의하기 위해 구조화해야 할 것으로는 다음과 같습니다.
- 마이크로 서비스가 제공하는 API
- 비즈니스 로직
- 이벤트 발행
- 패키지 구조
- 데이터 저장 처리 등등
외부 아키텍처와 같이 내부 아키텍처 또한 변화에 적응 가능하도록 유연하고 확장성 있게 구현해야 합니다.
마이크로 서비스 어플리케이션 영역은 실제로 개발자가 구현해야 할 부분입니다.
서비스의 비즈니스 로직에 집중할 수 있게
- 유연성
- 확장성
- 독립성 등
을 염두에 두고 설계한 여러 패턴들이 있습니다.
마이크로 서비스 어플리케이션에 사용되는 패턴들을 알아보겠습니다.
3-5-1. 프론트엔드 연계
우선 하나의 서비스는 보통 프론트엔드와 백엔드의 연계로 구현됩니다.
만약 프론트엔드가 단일 모노리스로 구성되어있다고 가정한다면,
MSA 로 구성된 백엔드와의 연계가 매끄럽게 이어지지 않을것입니다.
업무 기능 하나가 변경되어 재배포해야 할 상황을 가정해보겠습니다.
백엔드 부분에서는 수정된 내용이 독립적으로 배포 가능하지만,
프론트엔드는 하나의 덩어리(모노리스)이기 때문에 변경되지 않은 다른 기능들도 함께 빌드, 배포되어야 합니다.
따라서 이전에 백엔드가 모노리스였을 때 겪었던 문제들
- 독립적인 기능 변경 및 배포 불가
- 독립적인 기능 확장 불가 등
을 프론트엔드의 모노리스 서비스도 동일하게 겪을 수밖에 없습니다.
이를 위한 프론트엔드 설계 패턴으로 다음이 있습니다.
- UI 컴포지드 패턴
- 마이크로 프론트엔드 패턴
위 그림과 같이 프론트엔드도 백엔드의 마이크로 서비스처럼 기능별로 분리하고
이를 조합하기 위한 프레임 형태의 부모 창을 통해 각 프론트엔드를 조합해서 동작됩니다.
각각의 마이크로 프론트엔드 조각들은 비즈니스 구현을 위해 여러 개의 백엔드 마이크로 서비스 API 를 호출하게 됩니다.
하나의 기능을 변경했을 때 이를 제공하는 마이크로 프론트엔드와 백엔드를 구성하는 마이크로 서비스가 모두 변경되고 배포됩니다.
3-5-2. 마이크로 서비스 통신 패턴
프론트엔드와 백엔드, 백엔드와 백엔드 간의 호출에는 어떤 방법을 사용해야 할까요?
우선 동기 통신 방식 과 비동기 통신 방식 으로 나누어 집니다.
-
동기 통신 방식
클라이언트에서 서버 측 마이크로 서비스 REST API 를 호출할 때 사용되는 기본 통신 방법입니다.
(다양한 클라이언트 채널 연계나 라우팅 및 로드 밸런싱을 원활하게 하기 위해 중간에 API 게이트웨이를 둘 수 있습니다)단일 진입점인 API 게이트웨이를 통해 동기 호출하는 구성입니다.
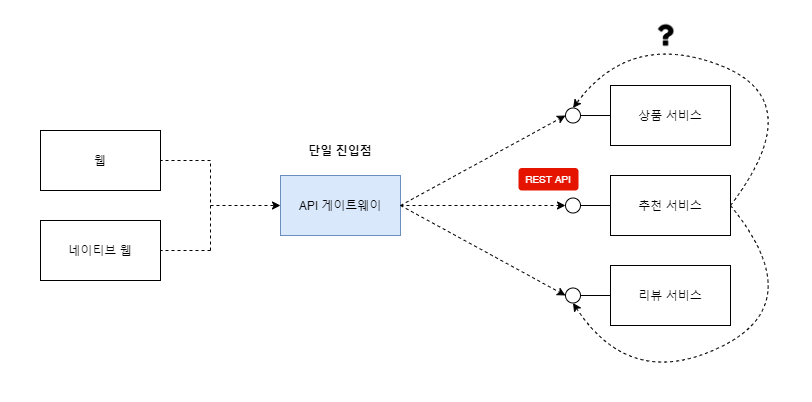 프론트엔드에서 백엔드 호출
프론트엔드에서 백엔드 호출이처럼 프론트엔드에서 백엔드 서비스 호출에는 동기 호출 방식을 사용하게 됩니다.
하지만 백엔드와 백엔드 간의 호출에는 동기 호출 방식이 고려되지 않습니다.
그 이유는 호출 중에 장애가 발생할 때 연쇄적인 장애전파 가 발생할 수 있기 때문입니다.동기식 호출은 요청하면 요청에 따른 응답이 오는 방식입니다.
직관적인 방식이라 가장 많이 쓰이고 구현하기 쉽지만, 호출 받은 서비스에 장애가 생긴다면 요청 보낸 서비스는 반응이 올 때까지 무한정 기다리게 됩니다.여러 서비스 간의 연계를 통해 업무를 처리해야 하는 마이크로 서비스 구조에서는
이 같은 상황에서 장애가 연쇄적으로 발생하게 됩니다.또한 서비스가 다른 서비스를 호출해서 얻은 정보를 이용해 기능을 제공한다는 의미는
해당 서비스간의 의존관계가 높다는 것을 의미하게 됩니다.
(이러한 방식은 독자적인 마이크로 서비스별 비즈니스 기능 처리를 어렵게 만듭니다)따라서 백엔드와 백엔드 간의 호출에는 장애 파급 효과, 의존 관계를 낮추기 위해 다른 통신 방법을 사용하게 됩니다.
-
비동기 통신 방식
백엔드와 백엔드 간의 호출에는 메시지 기반의 비동기 호출을 사용합니다.
이 방식은 동기 호출처럼 응답을 기다리지 않고 다른 다음 일을 처리합니다.
(물론 보낸 결과에 대한 완결성을 보장할 수 없습니다)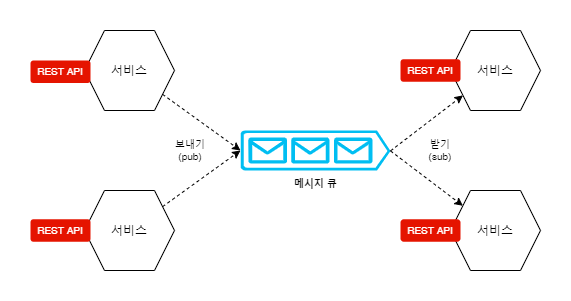 비동기 통신
비동기 통신이를 보장하기 위한 메커니즘으로 메시지 브로커를 활용하게 됩니다.
보통Apache Kafka,RabbitMQ,ActiveMQ을 사용하게 됩니다.위 그림에서 볼 수 있듯이 메시지를 보내는
생산자와 메시지를 받아 처리하는소비자가
직접 접속하지 않고메시지 브로커에 의해 연결되는 메커니즘입니다.
메시지 브로커에 메시지를 전달하고 자신의 일을 처리하면 메시지 브로커가 전송을 보장하게 됩니다.메시지 브로커는 메시지 처리 규모에 따라 확장이 가능합니다.
또한 서로 통신하는 서비스들이 물리적으로 동일한 시스템에 위치하거나 프로세스를 공유할 필요가 없습니다.
따라서 서비스 요구에 따라 늘어나거나 줄어들 수 있는 탄력성 높은 클라우드 플랫폼 환경에서 매우 효과적입니다.
3-5-3. 이벤트 기반 아키텍처
위에서 언급한 비동기 통신 방식을 이용해 느슨한 연계를 지향하는 아키텍처입니다.
- 이벤트를 생성 및 발행하는 발신자 (publisher)
- 해당 이벤트를 구독하여 이벤트를 받아 처리하는 수신자 (subscriber)
여기서 이벤트는 상태의 변화를 의미합니다.
카페에서의 커피 주문을 예시로 설명해보겠습니다.
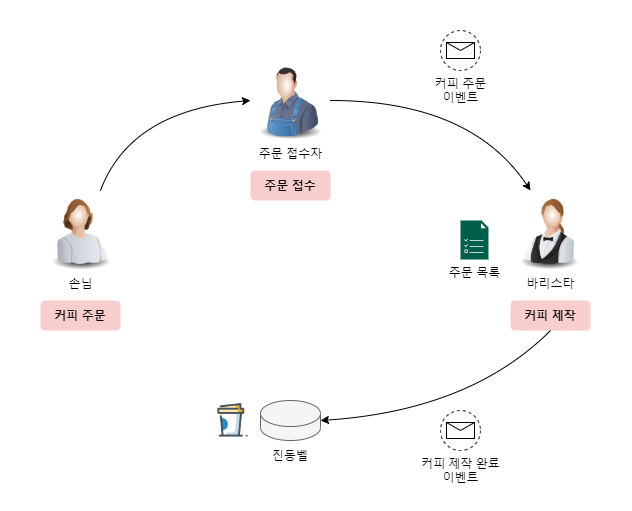
위 방식은 주문 접수 -> 커피 제작 -> 고객 전달이라는 하나의 무결하고 완결된 단위로 진행되지 않습니다.
주문 접수자는 고객으로부터 주문만 접수하며 커피 주문 이벤트를 발행하여 넘겨주기만 합니다.
바리스타는 해당 이벤트를 받아 커피만 생산하여 진동벨로 고객에게 완료 이벤트를 넘겨주게 됩니다.
이러한 방식은 여러 개의 주문을 받아 여러 개의 커피를 동시에 제작할 수 있는 효율성을 높입니다.
또한 주문이 많이 들어올 경우 바리스타를 추가 투입하여 생산량을 조절할 수도 있습니다.
이처럼 이벤트 기반 아키텍처는 이벤트를 생산하는 모듈과 이벤트에 대응하는 모듈을 분리하여
상호 독립적으로 동작하게 함으로써 병렬 처리를 촉진합니다.
또한 전달 메커니즘으로 앞에서 다룬 비동시 메시지 통신 방식을 선택하면 더욱더 효과적입니다.
이벤트 기반 아키텍처 + 비동기 통신 메커니즘을 함께 사용하는 마이크로 서비스를
이벤트 기반 마이크로 서비스 라고 합니다.
3-5-4. 저장소 분리 패턴
마이크로 서비스를 독립적으로 수정 및 배포하기 위한 저장소의 형태에 대해 알아보겠습니다.
기존 모노리식 시스템은 테이터 중심 어플리케이션을 주로 사용하는데,
모듈별로 격리 하지 않은 통합 저장소를 사용하여 다른 모듈에서의 호출을 허용하는 구조였습니다.
(이러한 방식은 SQL 조인 구문으로 다른 모듈이 소유권을 가지고 있는 데이터까지 함께 조합하여 호출하게 됩니다)
데이터 중심 어플리케이션은 비즈니스 로직이 대부분 데이터베이스 SQL 처리에 몰려잇는 경우가 대부분입니다.
이러한 구조는 특정 관계형 데이터베이스 벤더에 구속되고 복잡해져 유지보수가 어려워지고
성능 문제가 발생했을 때 SQL 구문 튜닝이나 저장소 증설에 의존할 수밖에 없습니다.
또한 아무리 여러 개의 마이크로 서비스로 분리하더라도 요청이 증가할 경우
서비스는 한가하고 여러 서비스에서 호출되는 통합 데이터베이스만 바쁜 상황이 되게 됩니다.
이를 보완하는 방법으로 저장소 분리 패턴이 사용됩니다.
저장소 분리 패턴은 각 서비스가 각자의 비즈니스를 처리하기 위한 데이터를 직접 소유하는 것을 뜻합니다.
자신이 소유한 데이터는 다른 서비스에 직접 노출하지 않고 각자가 공개한 API 를 통해서만 접근이 가능하게 됩니다.
- 정보 은닉
공개된 API 를 통해서만 데이터에 접근이 가능 - 폴리글랏 저장소
각 저장소를 자율적으로 선택 가능 - 디커플링
데이터를 통한 변경의 파급 효과를 줄여 서비스를 독립적으로 만듦
하지만 저장소를 격리함에 따라 이전에는 불거지지 않았던 문제가 생기게 됩니다.
즉, 여러개의 분산된 서비스에 걸쳐 비즈니스 처리를 수행해야 하는 경우
비즈니스 정합성 및 데이터 일관성을 어떻게 보장할 것인가에 대한 문제입니다.
이는 분산 트랜잭션 처리 패턴을 통해 일관된 트랜잭션으로 묶을 수 있습니다.
3-5-5. 분산 트랜잭션 처리 패턴
여러 개의 분산된 서비스를 하나의 일관된 트랜젝션으로 묶기 위해 분산 트랜잭션 처리 패턴을 사용하게 됩니다.
전통적인 방법으로 2단계 커밋 같은 기법이 있습니다.
분산 데이터베이스 환경에서 원자성을 보장하기 위해
분산 트랜잭션에 포함돼 있는 모든 노드가 커밋 되거나 롤백 하는 메커니즘입니다.
하지만 이 방법은 각 서비스에 잠금(lock in)이 걸려 발생하는 성능 문제를 야기해 효율적인 방법이 아닙니다.
특히 각 서비스가 다른 인스턴스로 로딩되기 때문에 통제하기 어렵습니다.
또한 MongoDB 같은 NoSQL 저장소는 해당 방식을 지원하지 않습니다.
클라우드의 가장 큰 장애는 네트워크 장애인 경우가 많은데, 특정 서비스의 트랜잭션이 처리되지 않을 경우
트랜잭션에 묶인 서비스가 즉시 영향을 받게 됩니다.
즉, 2단계 커밋 기법을 통한 분산 트랜잭션 처리는 독립적이지 않고 비자율적입니다.
마이크로 서비스의 독립적인 분산 트랜잭션 처리를 지원하는 패턴이 바로 사가(Saga) 패턴입니다.
사가 패턴은 각 서비스의 로컬 트랜잭션을 순차적으로 처리하는 패턴입니다.
로컬 트랜잭션과 보상 트랜잭션을 이용해 비즈니스 및 데이터의 정합성을 맞춥니다.
다른 트랜잭션의 결과에 따라 롤백이 필요하다면 보상 트랜잭션을 이용하여 롤백 처리를 하게 됩니다.
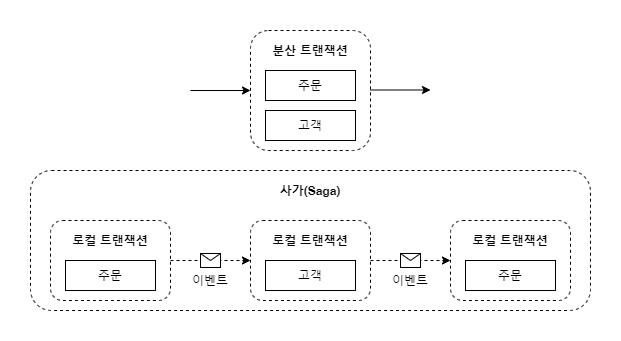
쉽게 말해 각 서비스의 트랜잭션을 로컬 트랜잭션으로 분리하고 이벤트 패턴을 통해 결과를 통신하는 방식입니다.
다음은 사가 패턴의 사례입니다.
사가 편성 방식은 코레오그레피 사가 방식과 오케스트레이션 사가 방식 두 종류로 나뉘며, 아래 사례는 코레오그레피 사가 방식입니다.
코레오그레피 방식은 의사결정과 순서를 참가자에게 맡기고 주로 이벤트 교환 방식으로 통신하며,
오케스트레이션 방식은 사가 오케스트레이터가 참여자에게 커멘드 메시지를 보내 수행할 작업을 지시하는 방식입니다.
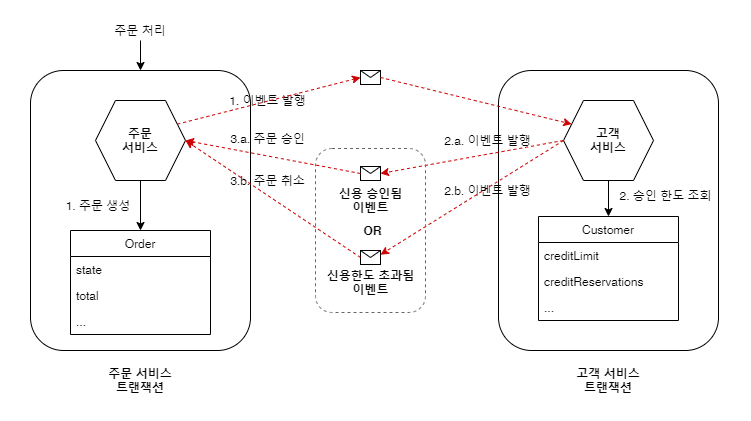
3-5-6. 결과적 일관성
모든 어플리케이션에는 비즈니스 처리를 위한 규칙이 있고, 이러한 규칙을 만족하도록 데이터 일관성이 유지되어야 합니다.
이전까지는 이 데이터 일관성이 실시간으로 반드시 맞아야 한다는 생각이 일반적이었습니다.
만약 서비스에 트래픽이 폭주한 경우를 생각해보면, 순차적인 동시 일관성을 추구하는 경우
어느 한 서비스에서 장애가 발생하게 되고 결국 지연 또는 장애 전파가 발생할 수 밖에 없습니다.
잘 생각해 보면 모든 비즈니스 처리가 반드시 실시간성을 요구하는 것이 아닙니다.
어떤 비즈니스는 데이터의 일관성이 실시간으로 맞지 않더라도 어느 일정 시점이 됐을 때 일관성을 만족해도 되는 것이 있습니다.
이러한 개념을 결과적 일관성이라 합니다.
결과적 일관성은 고가용성을 극대화합니다.
이 또한 사가 패턴과 이벤트 메시지 기반 비동기 통신을 적용하여 구현할 수 있습니다.
(각 서비스의 트랜잭션은 독립적이고 각 트랜잭션이 성공했을 때 상태 변경 이벤트를 통해 타 서비스와 연계됩니다)
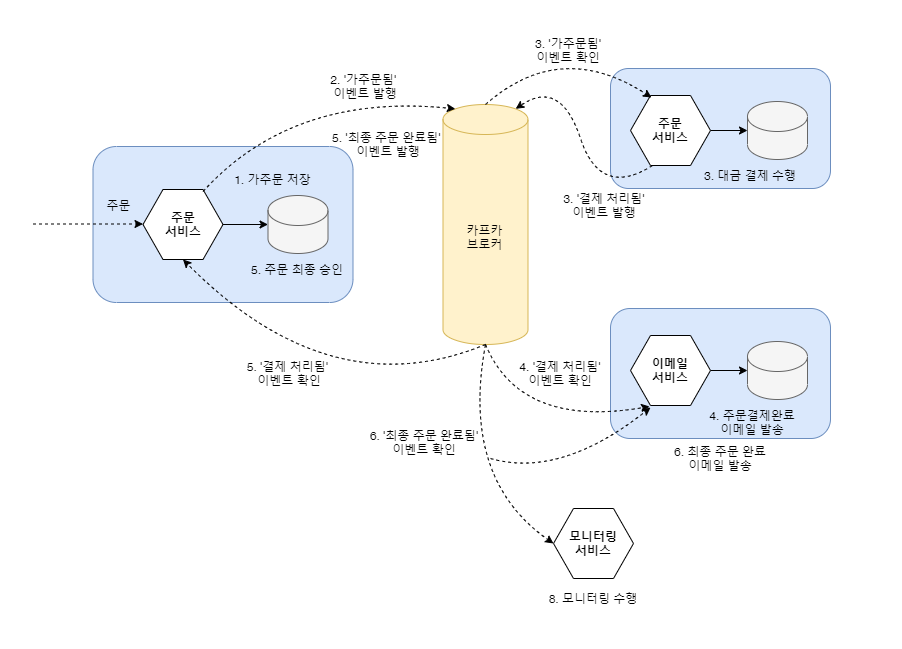
이처럼 이벤트 기반 아키텍처, 메시지 브로커, 사가 패턴으로 비즈니스 정합성을 결과적으로 보장할 수 있고
비즈니스 및 시스템 가용성을 극대화할 수 있습니다.
3-5-7. CQRS 패턴 (읽기와 쓰기 분리)
서비스별로 데이터 저장소를 나누어 놓아도 전통적인 DB 트랜젝션을 사용한다면 문제가 발생하게 됩니다.
인스턴스를 스케일 아웃하여 여러 데이터 처리를 할 경우 여러 읽기/수정 작업으로 인한 리소스 교착상태가 발생할 수 있습니다.
위 문제를 해결하기 위해 CQRS 패턴을 사용합니다. CQRS 패턴은 Command Query Responsibility Segregation, 즉 명령과 조회의 (책임) 분리를 의미합니다.
일반적으로 사용자의 비즈니스 요청은 (시스템의 상태를 변경하는) 명령과 (시스템의 상태를 나타내는) 조회로 나눌 수 있습니다.
하지만 실제 업무에서는 조회하는 부분이 많이 쓰이게 됩니다. [ 조회 > 입력, 수정, 삭제 ]
서비스 내에 이러한 CRUD 기능을 모두 넣어두면 조회 요청 빈도가 증가함에 따라 나머지 명령 기능은 비효율적일 수 밖에 없습니다.
조회와 명령, 두 서비스의 분리뿐만 아니라 물리적인 저장소를 따로 나누어 시스템의 부하를 줄일 수도 있습니다.
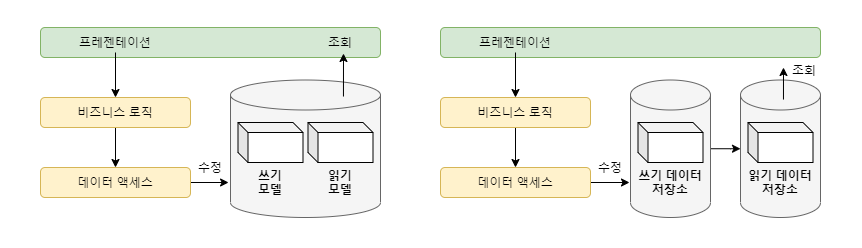
이 CQRS 패턴을 이벤트 메시지 주도 아키텍처와 연계한 예시 모습입니다.
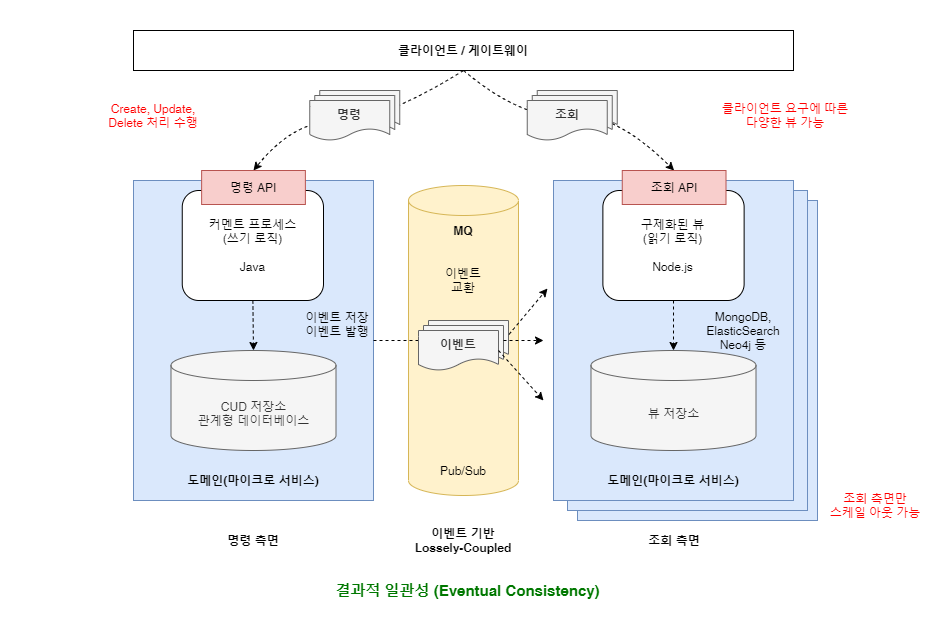
예시에 대한 설명입니다.
- 명령 측면 서비스에는 입력, 수정, 삭제 처리등 쓰기에 최적화된 관계형 데이터베이스를 사용합니다.
- 명령 서비스를 구현하는 프로그래밍 또한 업무 규칙을 표현하기 좋은 자바 언어를 사용합니다.
- 조회 측면 서비스에는 조회 성능이 높은 몽고디비나 엘라스틱서치 같은 NoSQL 데이터베이스를 사용합니다.
- 조회 서비스를 구현하는 프로그래밍은 조회를 간단하게 구현할 수 있는 스크립트 기반의 Node.js 를 사용합니다.
- 상대적으로 사용량이 많은 조회 서비스는 스케일 아웃하여 인스턴스를 증가시킬 수 있습니다.
- 두 서비스의 데이터 일관성을 유지하기 위해 이벤트를 발생시켜 메시지 브로커를 통해 데이터를 전달 받아 동기화 시킵니다.
- 실시간으로 데이터의 동기화가 이루어 지진않지만, 어느 시점이 되면 결과적으로 일치하게 되는 결과적 일관성을 추구합니다.
3-5-8. API 조합과 CQRS
각기 다른 서비스들의 기능을 연계해서 하나의 기능을 제공하는 경우에는 어떻게 해야 할까요.
첫 번째 방법은 API 조합입니다.
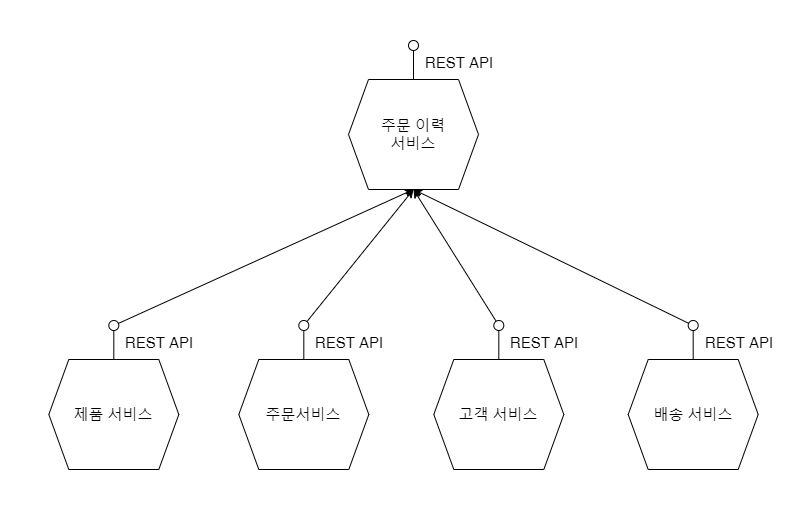
위 예시 그림과 같이 주문 이력 서비스는 제품, 주문, 고객, 배송 서비스의 정보가 모두 필요합니다.
각 기능을 제공하는 서비스를 조합하는 상위 마이크로 서비스를 만들어 조합된 기능을 제공할 수 있습니다.
하지만 이 구조는 상위 서비스(주문 이력 서비스)가 하위 서비스(제품, 주문, 고객, 배송 서비스)에 의존하는 결과를 가져옵니다.
의존도가 높아지면 하위 API 의 작은 변경이 상위에 크게 영향을 미치게 됩니다.
이러한 의존도를 낮추기 위해 CQRS 패턴을 이용할 수 있습니다.
주문 이력 서비스에 독자적인 저장소를 만들고, 주문 이력의 세세한 원천 정보를 각 하위 서비스로 부터 구독합니다.
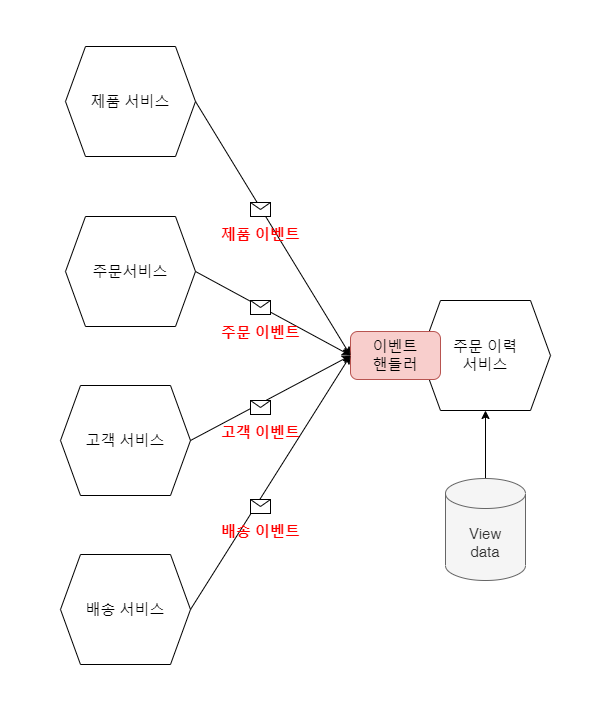
제품, 주문, 고객, 배송 서비스들 역시 독자적으로 자신의 저장소를 갖고 서비스를 제공하며
자신의 서비스의 정보가 변경되는 시점에 변경 내역을 각자의 변경 이벤트로 발행합니다.
이 방식은 다른 원천 서비스가 순간적인 장애가 발생한다 하여도 타 서비스에 영향을 주지 않게됩니다.
3-5-9. 쓰기 최적화: 이벤트 소싱 패턴
사가 패턴과 CQRS 패턴에서 비즈니스 불일치를 피하기 위해 저장소에 저장함과 동시에 메시지를 보내 동기화를 시켰습니다.
저장하는 일과 메시지를 보내는 작업은 언제가 완전하게 진행되어 함께 실행되어야 합니다(원자성).
하지만 객체 상태변화를 이벤트 메시지로 발행하고 동시에 객체 상태를 관계형 데이터베이스에 저장하기 위해
SQL 질의어로 변환하는 과정을 번거롭고 까다로울(임피던스 불일치) 뿐더러 두 기능을 수행하므로 빠르지도 않습니다.
이러한 문제들을 해결하기 위해 이벤트 소싱 패턴을 사용합니다.
기존에는 비즈니스 처리를 수행한 뒤 결괏값을 계산하여 데이터의 최종 상태로 저장하는 방식을 사용한다면,
이벤트 소싱 패턴은 발생된 비즈니스 이벤트(상태 트랜젝션 자체)를 이벤트 스트림 저장소에 저장합니다.
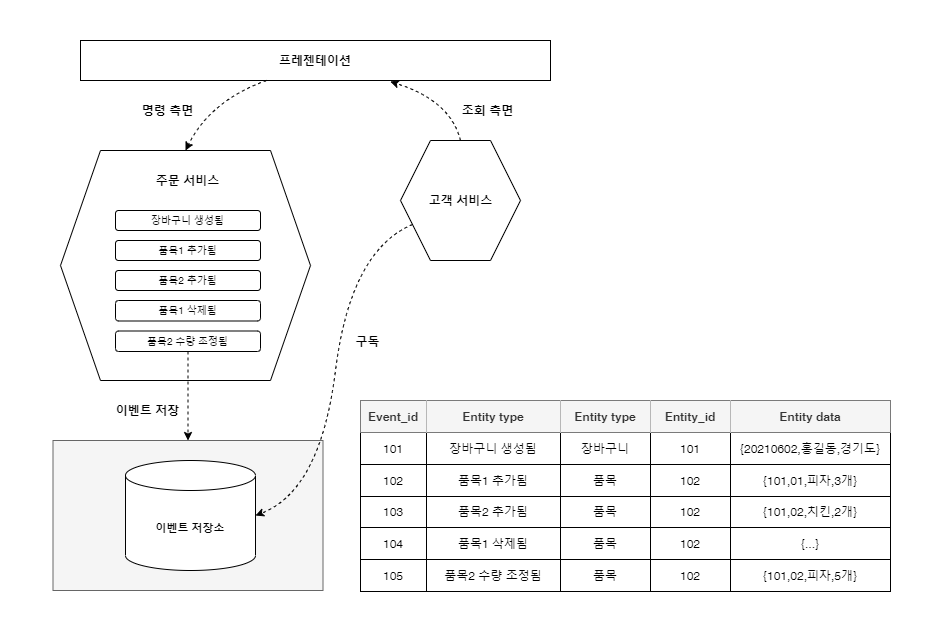
이렇게 이벤트를 저장만 한다면 메시지 브로커와 데이터 저장소를 분리하지 않아도 됩니다.
또한 복잡한 과정이 사라지므로 쓰기 속도가 훨씬 상향됩니다.
결과를 조회하기 위해서는 출발점부터 기록된 상태 변경 트랜젝션을 순차적으로 계산합니다.
처음부터 모든 트랜젝션을 계산하는 것이 부담된다면 특정 시간대에 상태를 계산한 후 스냅숏으로 저장하는 방식을 사용하면 됩니다.
명령 측면과 조회 흑면의 서비스가 이벤트 저장소에 대한 CRUD 를 모두 처리할 필요 없이 ‘입력/조회(CR)’ 만 처리하면 되므로,
변경 및 삭제가 발생하지 않기 때문에 리소스 교착상태가 발생하지 않게 됩니다.
이벤트는 한 번 발생한 후에 수정되지 않고 업데이트나 삭제 없이 입력되는 개념이라 동시성이나 정합성 등의 문제에 비교적 자유롭게 됩니다.
또한 상태를 저장하기 때문에 정확한 감사 로깅을 제공하고, 객체의 이전 상태 재구성이 간단해집니다.
3-6. 마이크로 서비스 어플리케이션 아키텍처
소프트웨어의 가치는 행위 가치와 구조 가치로 나뉘고, 소프트웨어를 정말로 부드럽게(Soft) 만드는 것은
구조가치이다. - 로버트 C. 마틴 저서 클린아키텍처 中
(여기서 행위 가치는 소프트웨어의 기능을 말하며, 구조 가치는 소프트웨어 아키텍처를 말합니다)
프로젝트 동안 어플리케이션 구조나 설계에 신경 쓰지 않고 오직 기능 구현에만 몰두한 소프트웨어는 유지보수가 어렵습니다. 새로운 형태의 UI 나 기술을 추가해야 한다고 했을 때 거의 처음부터 새로운 시스템을 만드는 것과 같은 수준으로 수정해야 하고, 사소한 기능 변경에도 사이드 이펙트를 알 수 없어 그에 따른 실제 변경 작업보다 다른 모듈의 영향도를 파악하기 위한 테스트에 더 많은 시간을 투자해야 하곤 합니다.
소프트웨어를 좀 더 부드럽게(Soft) 만들기 위해서는 바람직한 어플리케이션 아키텍처를 적용할 필요가 있습니다.
내부 설계 시 고려해야 할 각종 어플리케이션 아키텍처와 관련 패턴, 코드 스타일들을 살펴보겠습니다.
3-6-1. 관심사 분리
관심사를 왜 나눌까요?
- 인간의 인지능력은 한계가 있다. (한 번에 생각할 수 있는 양에 한계가 있음)
- 모든 소프트웨어 개발의 핵심은 복잡성을 극복하는 것이다.
즉, 한 번에 여러가지를 동시에 신경 쓰면 복잡성이 증가하므로 각각을 따로 분리하여야 관리가 쉬워질 것입니다.
소프트웨어의 핵심은 비즈니스 로직이라는 말이 있습니다.
비즈니스 로직이란 보통 시스템의 목적인 비즈니스 영역의 업무규칙, 흐름, 개념 을 표현합니다.
개발자의 역할은 문제 영역의 비즈니스 로직을 분석하고 이해하여 프로그래밍 언어라는 도구로 잘 표현하는 것입니다.
잘 표현한다는 것은 시스템의 각 영역이 처리하는 영역이 잘 분리되어 관리돼야 하고 변경이 유연해야 한다는 의미입니다.
이러한 설계 원칙을 관심사의 분리(SoC; Separation of Concerns)라 합니다.
이 원칙에 따라 각 영역은 고유 관심사에 의해 분리되고 집중돼야 합니다.
모듈화 및 계층화도 이 같은 원칙에 기인합니다.
특히 비즈니스를 표현하는 비즈니스 로직 영역과 기술 문제를 처리하기 위한 기술 영역은 철저히 분리하는 것이 좋습니다.
비즈니스 로직이 기술보다는 오랫동안 지속되고 안정적이어야 할 핵심 영역이기 때문입니다.
그러므로 기술에 영향을 적게 받도록(loosely coupled) 설계해야 합니다.
관심사의 분리는 전체 설계의 복잡도를 낮출뿐만 아니라 어플리케이션의 유지보수성 또한 높아집니다.
유지보수성이 높다는 의미는 특정 개인에 의존하기보다 어느 누구라도 손쉽게 어플리케이션을 이해하고 유지보수할 수 있음을 의미합니다.
데이터베이스 중심 아키텍처의 문제점
데이터 베이스 중심 아키텍처란 특정 관계형 데이터베이스에 의존한 데이터 모델링을 수행한 다음,
이 물리 테이블 모델을 중심에 두고 어플리케이션을 구현하기 위한 사고를 하는 방식입니다.
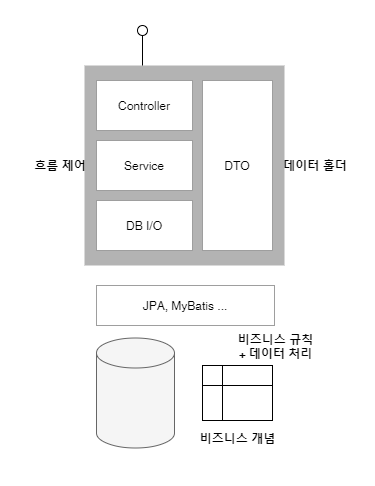
일반적으로 스프링 프레임워크를 활용하는 예시입니다.
- 컨트롤러, 서비스를 통해 흐름을 제어합니다.
- SQL 매핑 프레임워크로 JPA 또는 MyBatis 를 사용합니다.
이러한 구조에서 일반적으로 비즈니스 로직은 서비스에 존재해야 한다고 말하지만
서비스에 존재하게 될 로직은 흐름 제어 로직밖에 없게됩니다.
그 밖에 비즈니스 개념과 규칙들은 SQL 질의에 몰려있게 됩니다.
DTO(데이터 전송 객체) 는 질의를 통해 가져오는 정보 묶음의 역할밖에 할 수 없게됩니다.
간단한 로직의 경우에는 편하지만 업무가 복잡해질수록 점점 복잡성을 제어할 수 없게 됩니다.
업무 개념이 특정 저장 기술인 관계형 DB 테이블로 표현되고 업무가 복잡해질수록 업무 규칙이 SQL 과 섞여 표현되게 됩니다.
또한 이러한 시스템 구조에서는 저장소에 결합력이 강하므로 저장소 교체를 할 수 없게됩니다.
저장 기술과 비즈니스 로직이 끈끈하게 붙어 있기 때문입니다.
어플리케이션에서 할 일을 데이터베이스에서 하기 때문에 성능이 데이터베이스에 의존될 뿐만 아니라,
앞에서 클라우드 인프라를 사용할 때의 가장 큰 장점인 사용량에 유연하게 대처하는 자동 스케일 아웃이 의미가 없어지게 됩니다.
즉, 클라우드의 풍부한 자원 환경에서는 어플리케이션 자체의 성능보다는 확장성과 유연함이 더 중요하게 됩니다.
따라서 앞에서 언급한 관심사의 분리 원칙에 따라 비즈니스 로직 처리와 데이터 처리를 철저히 분리하는 것이 반드시 필요합니다.
3-6-2. 레이어드 아키텍처
레이어드 아키텍처는 물리적인 티어의 개념과 달리 논리적인 개념입니다.
티어는 물리적인 장비나 서버 컴퓨터 등의 물리층을 의미하고 레이어는 티어 내부의 논리적 분할을 의미하게 됩니다.
흔히 어플리케이션을 설계할 때 내부에서 처리하는 관심사를 논리적으로 구분하여 계층을 만듭니다.
다음은 레이어드 아키텍처 패턴의 전형적인 유형입니다.
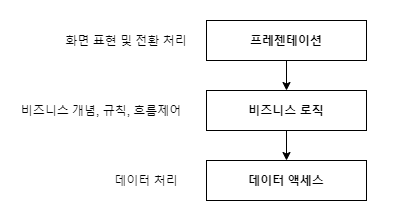
아키텍트가 의도하는 방향에 따라 여러 가지로 구분 가능하나 위 세 가지 계층으로 구분하는 것이 일반적입니다.
레이어드 아키텍처는 레이어 간 응집성을 높이고 의존도를 낮추기 위해 몇 가지 규칙을 둡니다.
- 상위 계층이 하위 계층을 호출하는 단방향성을 유지한다.
- 상위 계층은 하위의 여러 계층을 모두 알 필요 없이 바로 밑의 근접 계층만 활용한다.
- 상위 계층이 하위 계층에 영향을 받지 않게 구성해야 한다.
- 하위 계층을 자신을 사용하는 상위 계층을 알지 못하게 구성해야 한다.
- 계층 간 호출은 인터페이스를 통해 호출하는 것이 바람직하다.
위 구조는 의존성 역전 원칙(DIP; Dependency Inversion Principle)을 만족하게 됩니다.
의존성 역전 원칙 : 유연성이 극대화된 시스템에서는 소스코드 의존성이 추상에 의존하며, 구체에는 의존하지 않아야 한다.
즉, 추상 인터페이스를 통한 통신이 상-하위 계층간 의존성을 분리시켜주고,
하위 계층에서는 추상적 인터페이스를 만족하는 다양한 방식의 구현체를 선택적으로 적용할 수 있게 됩니다.
하지만 위 구조는 개방 폐쇄의 원칙(OCP; Open-Closed Principle)까지 살펴본다면 문제가 있습니다.
계방 폐쇄의 원칙 : 소프트웨어 개체는 확장에는 열려 있어야 하고 변경에는 닫혀 있어야 한다.
일반적인 레이어드 아키텍처가 OCP 에 위배되는 까닭은 모든 계층이
각기 자신이 제공하는 기능에 대한 추상 인터페이스를 직접 정의하고 소유하고 있는 구조이기 때문입니다.
제어 흐름은 상위 계층에서 하위 계층으로 흐르게 되고 (의존성 역시 제어 흐름 방향대로 따르게 됩니다)
결국 상위 계층은 하위 계층의 추상 인터페이스에 의존하게 되고, 그 계층이 정의하는 추상 특성의 한계를 벗어날 수 없게 됩니다.
따라서 하위 계층이 확장될 때, (닫혀 있어야 할)상위 계층이 하위 계층에서 정의한 추상 특성에 영향을 받아 OCP 를 위배하게 됩니다.
이를 해결하기 위해서는 하위 계층에서 구현해야 할 인터페이스를 좀 더 고수준의 상위 계층에서 정의하게 함으로써
기존의 위에서 아래로 흘렀던 의존 관계를 역전 시키고(DIP 만족) 고수준 영역이 저수준 영역의 변경에 영향을 받지 않게 합니다(OCP 만족).
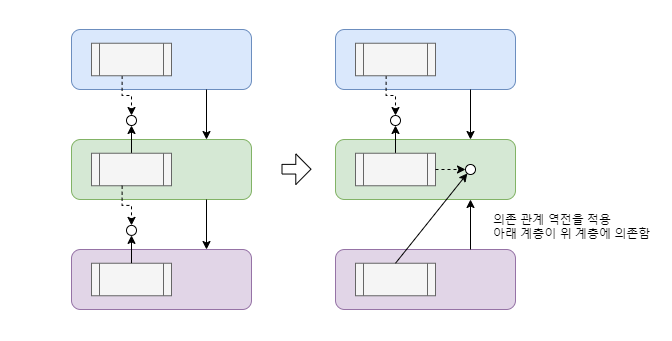
3-6-3. 헥사고날 아키텍처
레이어드 아키텍처에 DIP 를 적용해도 한계가 있게 됩니다.
현대 어플리케이션에는 저수준 계층인 프레젠테이션 계층, 데이터 액세스 계층 외에도 다양한 인터페이스를 필요로 합니다.
레이어드 아키텍처와 같은 단방향 계층구조에서는 이러한 점을 지원하기 어렵습니다.
헥사고날 아키텍처는 ‘포트 앤드 어댑터 아키텍처’ 라고도 하며 포트와 어댑터를 통해 다양한 인터페이스를 적용할 수 있습니다.
헥사고날 아키텍처 구조는 다음과 같습니다.
- 고수준의 비즈니스 로직을 표현하는 내부 영역
- 순수한 비즈니스 로직을 표현하는 기술 독립적인 영역
- 외부 영역과 연결되는 포트를 가지고 있음
- 인터페이스 처리를 담당하는 저수준의 외부 영역
- 외부 요청을 처리하는 인바운드 어댑터
- 비즈니스 로직에 의해 호출되어 외부와 연계되는 아웃바운드 어댑터
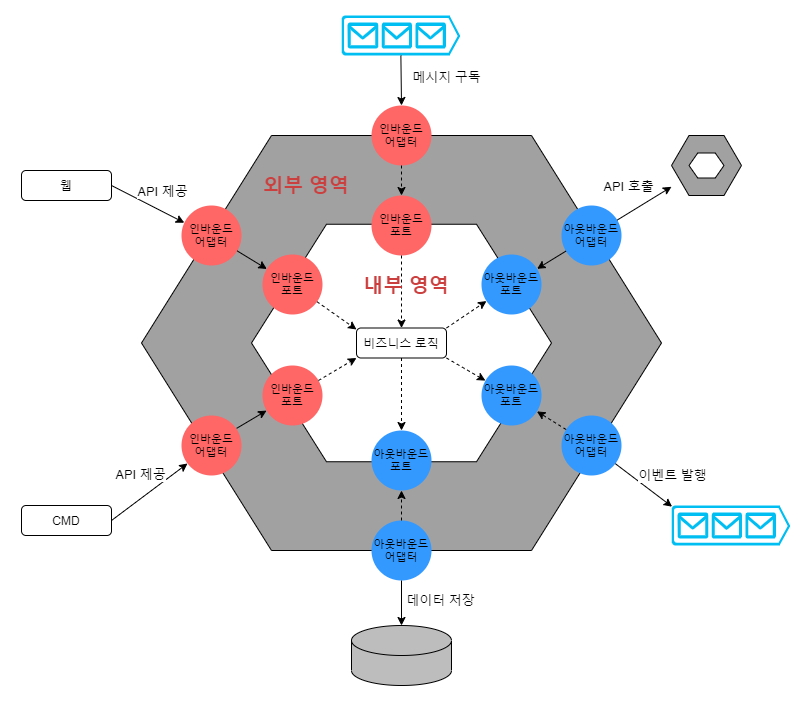
헥사고날 아키텍처 포트의 특징은 다음과 같습니다.
- 고수준의 내부 영역이 외부의 구체 어댑터에 전혀 의존하지 않습니다. (포트에 의해)
- 인바운드 포트는 내부 영역 사용을 위해 표출된 API 입니다.
- 아웃바운드 포트는 외부를 호출하는 방법을 정의합니다.
- 아웃바운드 포트가 외부의 아웃바운드 어댑터를 호출해서 외부 시스템과 연계하는 것이 아니라
아웃바운드 어댑터가 아웃바운드 포트에 의존해서 구현됩니다. (DIP 원칙)
헥사고날 아키텍처 어댑터의 특징은 다음과 같습니다.
- 인바운드 어댑터의 종류 예시
- REST API 컨트롤러
- 웹 페이지 스프링 MVC 컨트롤러
- 커맨드 핸들러
- 이벤트 메시지 구독 핸들러 등
- 아웃바운드 어댑터 종류 예시
- DAO (Jpa, MySQL, NoSQL 등등)
- 이벤트 메시지 발행 클래스
- 외부 서비스 호출 프록시 등
3-6-4. 클린 아키텍처
클린 아키텍처는 로버트 C. 마틴이 제안한 아키텍처로서 헥사고날 아키텍처의 아이디어와 매우 유사합니다.
마틴은 ‘소프트웨어는 행위 가치와 구조 가치의 두 종류 가치를 가지며, 구조 가치가 더 중요하다’고 말합니다.
(여기서 행위 가치는 소프트웨어의 기능을 말하며, 구조 가치는 소프트웨어 아키텍처를 말합니다)
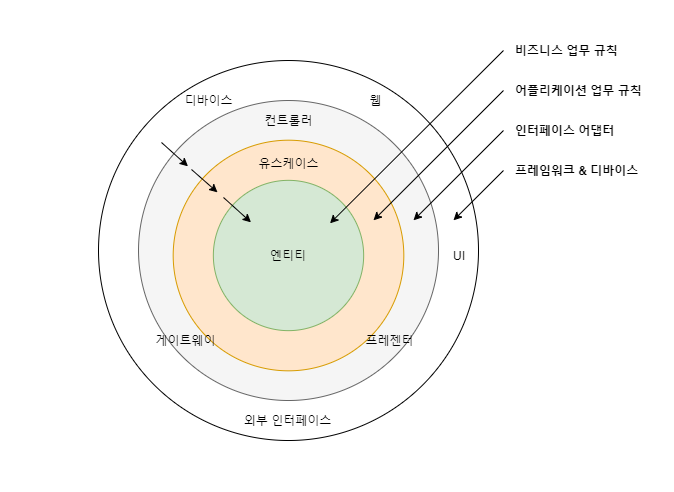
위 그림과 같이 클린 아키텍처는 여러 겹으로 둘러싸인 영역으로 표현합니다.
클린 아키텍처 역시 고수준(원 안쪽) 영역이 저수준 영역을 알게 해서는 안 됩니다.
(즉, 제어 흐름이 안쪽으로 흐르게 됩니다)
- 엔티티
비즈니스 업무 규칙은 사업적으로 수익을 얻거나 비용을 줄일 수 있는 규칙 또는 절차를 뜻합니다.
이러한 업무 규칙은 시스템으로 자동화하여 사용하는 것이 효율적입니다.
핵심 업무 규칙은 보통 데이터를 요구하며 이 둘은 본질적으로 결합돼 있기 때문에 객체로 쉽게 만들 수 있습니다.
이러한 유형을 ‘엔티티’ 객체라 합니다.
- 유스케이스
유스케이스는 자동화된 시스템을 사용하는 처리 절차를 기술합니다.
즉, 어플리케이션에 특화된 업무 규칙을 표현하며, 엔티티 내부의 핵심 업무 규칙을 호출하여 시스템을 사용하는 흐름을 담습니다.
엔티티는 간단한 객체여야 하며, 프레임워크 데이터베이스 또는 기타 복잡한 것에 의존해서는 안 되고 유스케이스객체를 통해서만 조작해야 합니다.
- 나머지 세부사항
유스케이스 외 감싸고 있는 나머지 모든 영역이 세부사항입니다.
세부사항과 유스케이스의 관계를 의존 관계 역전의 원칙(DIP)을 이용해 플러그인처럼 유연하게 처리해야 합니다.
(이처럼 명확한 겹합의 분리는 테스트 용이성 및 개발 독립성, 배포 독립성을 강화합니다)
3-6-5. 마이크로 서비스 내부 구조
위에서 다룬 레이어드 아키텍처, 헥사고날 아키텍처, 클린 아키텍처들은
기존 모노리스 어플리케이션 유형에도 통용되는 아키텍처로서 마이크로 서비스만들 위한 아키텍처는 아닙니다.
그렇지만 이러한 아키텍처 구조가 마이크로 서비스가 지향하는 유연성, 확장성을 지원하는 구조 이기에 강조되어지고 있습니다.
그럼 이러한 아키텍처를 참고하여 바람직한 마이크로 서비스 내부 구조를 정의해 보겠습니다.
3-6-5-1. 바람직한 내부 아키텍처: 클린 마이크로 서비스
마이크로 서비스 아키텍처는 점점 복잡해지는 모노리스 소프트웨어를 통제하기 위해 각 기능들을 쪼개어 복잡성을 덜어냅니다.
그렇지만 분리해도 복잡성은 여전히 이전되고 그 안의 복장성 을 통제할 필요가 있다는 사실은 변하지 않게 됩니다.
마이크로 서비스 내부 구조를 정의할 때 반드시 내부 구조의 다양성 을 고려해야 합니다.
왜냐하면 자율적인 마이크로 서비스 팀에 의한 폴리글랏한 내부 구조를 가질 수 있기 때문입니다.
아래 그림과 같이 다양한 아키텍처 패턴의 서비스가 제공될 수 있습니다.
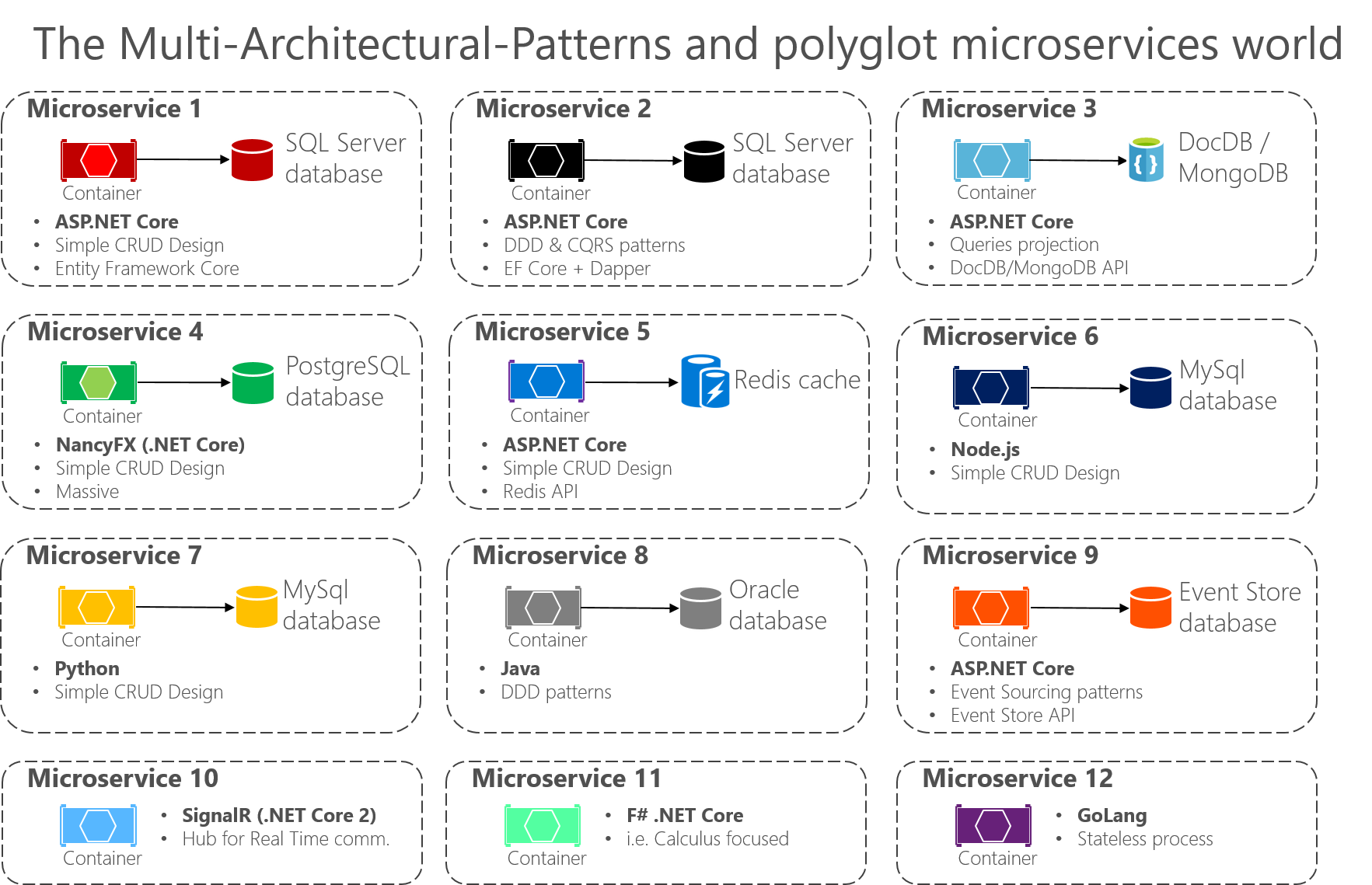
보다시피 각 서비스의 개발 언어와 저장소가 다양하고 아키텍처 구조까지도 다양하다는 사실을 알 수 있습니다.
이처럼 마이크로 서비스 아키텍처에서 각 서비스는 각기 목표와 활용도에 따라 명확하게 분리돼야 하고,
각 서비스 목적에 따라 적절한 개발 언어 및 저장소, 내부 아키텍처를 정의하는 것이 바람직합니다.
조회나 아주 간단한 기능의 경우 헥사고날이나 클린 아키텍처 방식의 구조를 고수할 필요는 없을 것입니다.
그렇지만 비즈니스 규칙이 복잡할 경우 헥사고날이나 클린 아키텍처 구조 기반으로 정의하는 것이 바람직할 것입니다.
위에서 언급한 3가지 아키텍처가 지향하는 바를 모아 바람직한 마이크로 서비스 내부 구조를 정의해 보겠습니다.
우선 3가지 아키텍처가 지향하는 원칙들을 정리해 보겠습니다.
- (지향하는 관심사에 따라) 응집성은 높이고 의존도는 낮춰야 한다.
- 비즈니스 로직 영역과 기술 영역을 분리해야 한다
- 저수준의 외부 영역(세부 기술 중심)과 고수준의 내부 영역(핵심 업무 규칙 중심)으로 구분한다.
- 저수준 영역에서 고수준 영역으로 의존 방향이 향해야 한다. (반대로 의존하면 안됨)
- (자바와 같은) 인터페이스 및 추상 클래스를 지원하는 언어의 경우, 구체 클래스가 추상 인터페이스에 의존하는 DIP 를 적용한다.
- 인터페이스는 고수준의 안정된 영역에 존재해야 하며, 저수준의 어댑터가 이를 구현한다.
이러한 원칙을들을 준수하며 아래와 같은 마이크로 서비스 아키텍처 구조가 정의됩니다.
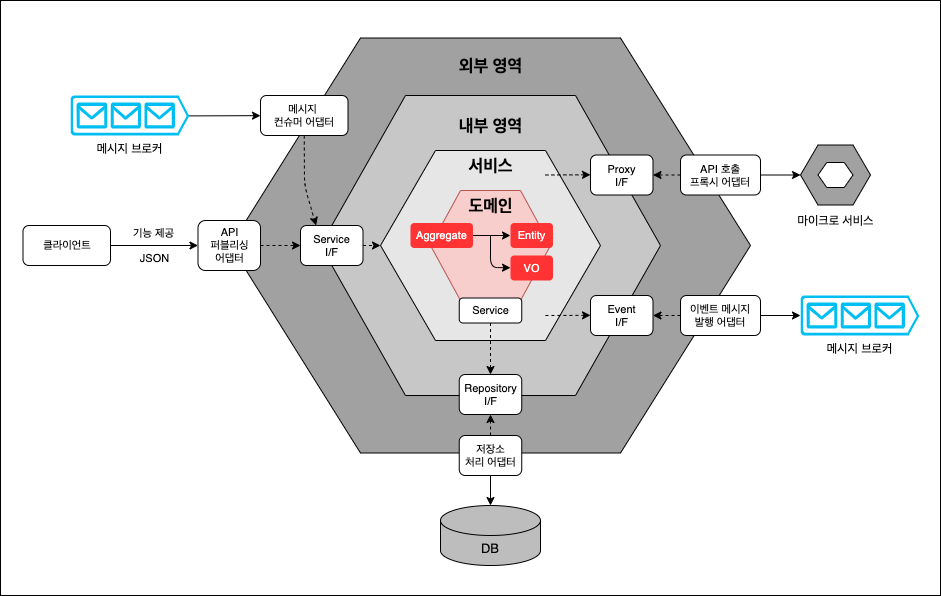
3-6-5-2. 내부 영역 - 업무 규칙
내부 영역 구현에 필요한 패턴을 알아보겠습니다.
우선 내부 영역은 다음과 같이 구성됩니다.
- 서비스 인터페이스
- 서비스 구현체
- 도메인
- 리포지토리 인터페이스
- 도메인 이벤트 인터페이스
- API 프록시 인터페이스
서비스 인터페이스는 외부 영역이 내부 영역에 대해 너무 많이 알지 못하게 가리는 역할을 합니다.
또한 인터페이스를 통해 외부/내부 서비스의 구현 및 테스트를 독자적으로 진행할 수 있도록 합니다.
(인터페이스가 없이 서비스 구현체를 직접 호출한다면 서비스의 구현이 끝난 후에 다음 작업이 진행될 수 밖에 없습니다)
리포지토리 인터페이스, 도메인 이벤트 인터페이스, API 프록시 인터페이스는 DIP 를 지원합니다.
더 안정된 곳인 고수준 영역에 인터페이스가 존재하고 저수준의 외부 어댑터가 이러한 인터페이스를 구현하게 됩니다.
다음으로 비즈니스 로직의 핵심인 서비스와 도메인입니다.
도메인은 비즈니스 개념을 표현하고 서비스는 도메인을 활용해 시스템 흐름 처리를 수행합니다.
서비스와 도메인의 관계를 구현할 때 참고할 만한 유용한 패턴들이 있습니다.
바로 마틴 파울러의 «엔터프라이즈 어플리케이션 아키텍처 패턴» 에서 언급한 트랜젝션 스크팁트 패턴과 도메인 모델 패턴입니다.
-
트랜젝션 스크립트 패턴
비즈니스 행위를 수행하는 모든 책임이 서비스에 있는 패턴입니다.
서비스가 비즈니스 절차에 따라 절차적으로 도메인 객체를 이용해 모든 처리를 수행합니다.
이런 방식은 서비스가 많은 로직을 보유하게 됨으로써 시스템이 복잡해질수록 비대해질 수 있습니다.
DTO(도메인 객체)는 점점 정보 묶음의 역할만 수행하게 됩니다.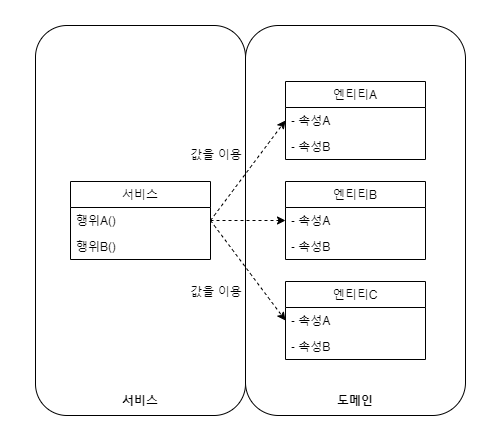 트랜젝션 스크립트 패턴
트랜젝션 스크립트 패턴
-
도메인 모델 패턴
도메인 객체가 데이터뿐만 아니라 비즈니스 행위를 가지고 있으며, 도메인이 소유한 데이터는 행위에 의해 은닉됩니다.
도메인 객체는 각 비즈니스 개념 및 행위에 대한 책임을 수행하고, 서비스는 비즈니스 유스케이스를 구현하기 위해
서비스의 행위를 도메인 객체에 일부분 위임해서 처리하게 됩니다.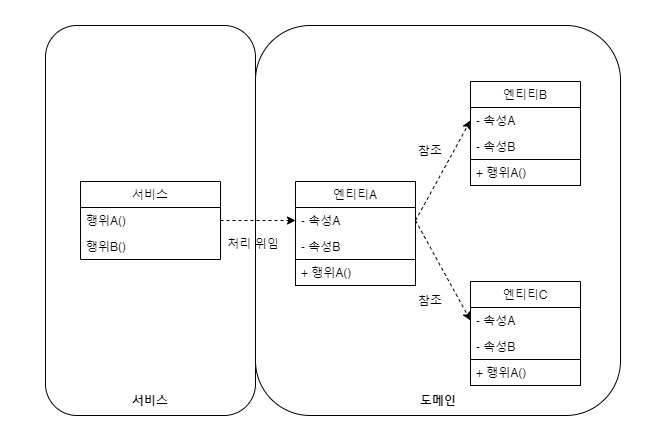 도메인 모델 패턴
도메인 모델 패턴서비스의 책임들이 도메인으로 적절히 분산되기 때문에 서비스가 비대해지지 않고 단순해집니다.
또한 여기서 더 진화해서 도메인 주도 설계의 애그리거트 패턴을 적용할 수 있습니다.
-
애그리거트 패턴
점점 복잡도가 높아지는 객체 모델링의 단점을 보완할 수 있는 패턴입니다.
도메인 모델링을 하다 보면 객체 간의 관계를 참조로 표현하는데,
참조로 정의할 경우 일대다(1:N) 관계의 객체를 쉽게 사용할 수 있는 장점이 있습니다.
그렇지만 업무가 복잡해지면 참조로 인한 다단계 계층 구조가 생기고 점점 참조 관계가 무거워집니다.또한 이러한 복잡한 도메인 모델을 내부 경계가 불명확합니다.
예를 들어 어떤 도메인 모델이 일대다 관계를 맺고 있고, 다(many) 측에 있는 클래스의 총 개수를
일(one) 측에 있는 클래스에서 집계해야 하는 규칙이 있다고 가정하겠습니다.서비스에서 이러한 로직을 처리할 때 다측에 클래스가 추가되면 일 측의 클래스에서 집계한 값을 수정해야 합니다.
두 클래스가 갖는 비즈니스 일관성을 맞춰야 하기 때문입니다.
도메인 모델이 점점 커짐에 따라 이러한 문제가 복잡해지고 꼬이게 됩니다.이를 개선한 방안으로 최상위에 존재하는 엔티티(Root Entity)를 중심으로 개념의 집합을 분리한 것이 애그리거트 패턴입니다.
복잡한 모델을 세 덩어리의 개념으로 분리한 예입니다.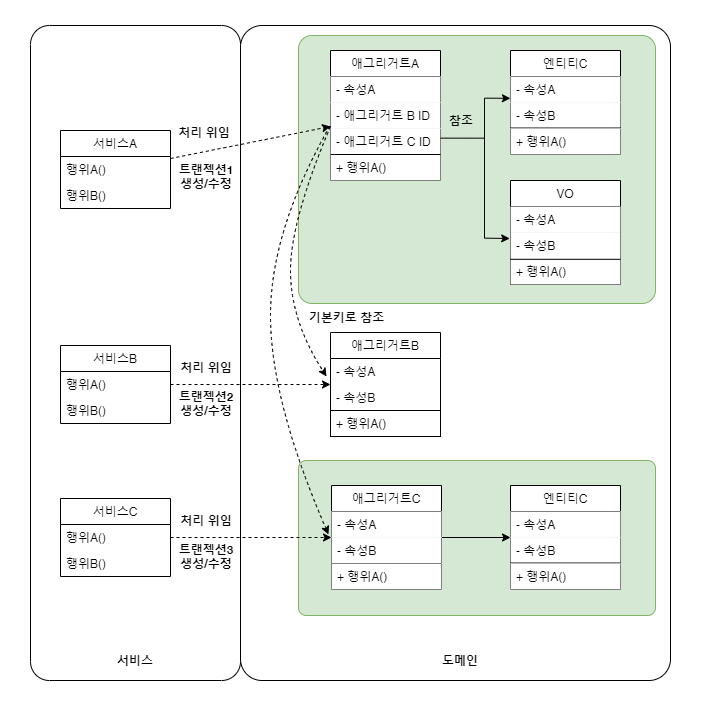 애그리거트 패턴
애그리거트 패턴위 예시와 같이 애그리거트는 1개 이상의 엔티티와 값 객체(Value Object)로 묶여 구성됩니다.
애그리거트를 한 단위로 일관되게 처리하기 위해 다음과 같은 규칙을 부여합니다.- 애그리거트 투르만 참조한다.
- 애그리거트 내 상세 클래스를 바로 참조하지 않고 루트를 통해 참조해야 한다. (수정할 떄도 마찬가지)
- 애그리거트 간의 참조는 객체를 직접 참조하는 대신 기본 키를 사용한다.
- 기본 키를 사용하면 느슨하게 연관되고 수정이 필요하지 않은 애그리거트를 함께 수정하는 실수를 방지한다.
- 하나의 트랜젝션으로 하나의 애그리거트만 생성 및 수정한다.
3-6-5-3. 외부 영역 - 세부사항
외부 영역은 내부 영역의 서비스 인터페이스를 사용하는 인바운드 어댑터와
내부 영역에서 선언한 아웃바운드 인터페이스를 구현하는 다양한 어댑터로 구성됩니다.
어댑터는 플러그인처럼 언제든지 교체되거나 확장될 수 있어야 합니다.
따라서 내부 영역이 먼저 정의된 후에 외부 영역의 세부사항은 늦게 정의돼도 상관없도록 해야 합니다.
그럼 어댑터들이 주로 하는 작업인 동기/비동기 통신 및 저장소 처리에 필요한 각 어댑터 구현 메커니즘과 고려사항을 알아보겠습니다.
- API 퍼블리싱 어댑터
REST API 를 발행하는 인바운드 어댑터입니다.
명시적 REST 리소스 명칭을 정의하고, 각 메서드가 의도에 맞게 서비스 인터페이스를 호출합니다.
엔티티를 직접 제공하지 않고 API 필요에 맞는 DTO 를 생성하여 변환 및 매핑하여 전달하는 것이 바람직합니다.
(엔티티를 직접 제공할 경우 클라이언트에 도메인 규칙이 유출됩니다)
- API 프록시 어댑터
다른 서비스의 API 를 호출하는 아웃바운드 어댑터입니다.
내부 영역에 정의된 프록시 인터페이스를 구현하며, 다른 서비스의 API 는 REST API 가 될 수도 있고
소켓이나 SOAP 프로토콜을 사용하는 API 일 수도 있습니다.
- 저장소 처리 어댑터
우선 구현을 위한 데이터 처리 메커니즘을 선택해야 합니다.
OR 매핑 방식과 SQL 매핑 방식을 사용할 수 있으며, 내부 영역에서 어떤 구조를 선택하든 둘 다 사용할 수 있습니다.
(일반적으로 트랜잭션 스크립트 패턴은 SQL 매핑방식, 도메인 모델 패턴은 OR 매핑 방식을 많이 선택합니다)- OR 매핑 방식
OR 매퍼가 런타임 시 저장도에 따라 자동으로 질의문을 생성합니다.
따라서 SQL 작성에 따르는 개발자의 작업량을 줄일 수 있습니다.
JPA 또는 스프링 데이터를 사용하여 구현합니다. - SQL 매핑 방식
SQL 질의문을 수동으로 작성하여 세밀한 SQL 제어에 많이 사용됩니다.
마이바티스 프레임워크를 사용하여 구현합니다.
- OR 매핑 방식
-
도메인 이벤트 발행 어댑터
앞서 외부 아키텍처에서 서비스 간 비동기 메시지 통신에 대해 살펴봤습니다.
여기서 전달 대상이 되는 정보가 도메인 이벤트 입니다.도메인 이벤트는 어떤 사건에 따른 상태 변경 사항을 말하는데,
주문됨,주문 취소됨등의 명칭을 갖는 클래스로 구현되며,
컨슈머(Consumer)에게 전달되기 위해 도메인 이벤트 발행 어댑터를 통해 발행됩니다.
(애그리거트 패턴을 적용할 경우 도메인 이벤트는 애그리거트에서 발생한 사건이 됩니다)실제도 도메인 이벤트가 생성되는 위치는 내부 영역이며, 도메인 이벤트 발행 어댑터는 내부 영역의
이벤트 인터페이스를 구현해서 아웃바운드로 특정 메시지 큐나 스트림 저장소에 발행하는 역할을 수행합니다.
- 도메인 이벤트 핸들러
위의 도메인 이벤트 발행 어댑터가 있다면 당연히 수신할 수 있는 인바운드 어댑터도 필요합니다.
이벤트 핸들러는 외부에서 발행된 도메인 이벤트를 구독해서 내부 영역으로 전달하는 일을 수행합니다.
이벤트 상태에 따라 적절한 서비스 인터페이스를 호출하여 내부 영역에 이벤트를 전달합니다.
3-6-6. 코드 스타일
마이크로 서비스 내부 아키텍처 코드 스타일입니다.
소스코드는 아래 저장소를 확인해주세요.
[ 마이크로 서비스 내부 아키텍처 코드 스타일 ]
지금까지 마이크로 서비스에 사용되는 내부 아키텍처 구조를 살펴봤습니다.
부드러운(Soft) 소프트웨어를 만들기 위해선 클라우드 플랫폼이나 쿠버네티스 같은
외부 아키텍처를 적용하는 것 만으로도 유연하고 기민해 질 수 있습니다.
그렇지만 시스템의 핵심은 소프트웨어이고, 실제로 비즈니스를 제공하는 것은 마이크로 서비스입니다.
기민한 비즈니스를 제공하기 위해서 내부 또한 유연해야 하며 서비스 간 관계도 이벤트를 기반으로 느슨하게 구현하여야
비로소 서비스를 독립적으로 확장, 변경, 배포할 수 있게됩니다.
이러한 구조의 핵심은 어떻게 어플리케이션의 관심사를 철저하게 분리할 수 있느냐(SoC) 입니다.
그리고 가장 중요한 것은 비즈니스 표현과 변화가 잦은 기술 표현을 나누는 것입니다.
가장 빨리 가는 방법은 제대로 가는 것입니다.
처음에는 오래 걸리고 힘들고 불편하겠지만 꼼수를 쓰지 않고 원칙을준수하는 것이 길게 보면 가장 빠른 법입니다.
다음장 은 어떠한 도구와 전략을 사용하여 설계한 내용을 구현할지에 대해 다뤄보겠습니다.
Table of Contents
참고
- 도메인 주도 설계로 시작하는 마이크로서비스 개발 (한정헌, 유해식, 최은정, 이주영 저)
- 테스트 주도 개발로 배우는 객체 지향 설계와 실천 (Steve Freeman, Nat Pryce 저)
- Clean Code (Robert C. Martin 저)
- Mastering Spring 5.0 (Ranga Rao Karanam 저)
- JAVA 객체 지향 디자인 패턴 (정인상, 채흥석 저)